МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
Федеральное государственное бюджетное образовательное
учреждение высшего образования
«ДАГЕСТАНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ»
Факультет информатики и информационных технологий
КУРС
ЛЕКЦИЙ
Омаровой Эльмиры Шахбановны
по
дисциплине
«Теория алгоритмов»
КАФЕДРА ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
И МОДЕЛИРОВАНИЯ ЭКОНОМИЧЕСКИХ ПРОЦЕССОВ
Образовательная программа
09.03.03 Прикладная информатика
Профили
подготовки:
Прикладная информатика в экономике,
Уровень высшего образования
Бакалавриат
Форма обучения
очная
Статус дисциплины: вариативная
Махачкала 2016 г.
Модуль
I. Понятие алгоритма, вычислимые функции.
Тема
1. Интуитивное понятие алгоритма. Формализация и обобщение понятия алгоритма.
1.1
Краткая характеристика изучаемой дисциплины, предмет курса, задачи курса.
1.2
Интуитивное понятие алгоритма. Исторический обзор.
1.3
Практическое применение результатов теории алгоритмов
1.4
Формализация понятия алгоритма.
2.1 Понятие разрешающей процедуры и вычислимой
функции.
2.2 Формальная теория вычислимости.
Тема
3. Вычислимость по Тьюрингу.
3.1 Машина Тьюринга: определение, механизм
работы.
3.2 Компоненты машины Тьюринга. Тезис Тьюринга.
4.1 Тезис Черча и его значимость. Элементарные
шаги
4.2 Вычисления с помощью современных
вычислительных машин.
Тема
5. Рекурсивные и рекурсивно перечислимые ии
5.1 Понятие рекурсии. Рекурсивные функции.
5.2
Рекурсивные и рекурсивно перечислимые множества и предикаты
Тема
6. Сложность алгоритмов и конечных
объектов
6.1
Меры сложности вычислений алгоритмов
6.2
Сложность конечных объектов
Модуль
IV. Формальные языки класса P
и NP.
Тема
7. Теория полиномиальной вычислимости.
7.1 Формальные языки класса P.
7.2 Замечания к задачам класса P
Тема
8.Недетерминированная машина Тьюринга и языки класса NP
8.1 Недетерминированная машина Тьюринга и языки
класса NP
8.2
Замечания к задачам класса NP
Перечень
основной и дополнительной учебной литературы, необходимой для освоения
дисциплины.
Модуль I. Понятие алгоритма, вычислимые функции.
Тема 1. Интуитивное понятие алгоритма. Формализация и обобщение понятия алгоритма.
1.1 Краткая характеристика изучаемой дисциплины, предмет курса, задачи курса.
Теория алгоритмов - это наука, изучающая общие
свойства и закономерности алгоритмов, разнообразные формальные модели их
представления. На основе формализации понятия алгоритма возможно сравнение
алгоритмов по их эффективности, проверка их эквивалентности, определение
областей применимости.
Разработанные
в 1930-х годах разнообразные формальные модели алгоритмов (Э. Пост, А. Тьюринг,
А. Черч), равно как и предложенные в 1950-х годах модели А.Н. Колмогорова и А.А.
Маркова, оказались эквивалентными в том смысле, что любой класс проблем,
разрешимых в одной модели, разрешимы и в другой.
В настоящее
время полученные на основе теории алгоритмов практические рекомендации получают
всё большее распространение в области проектирования и разработки программных
систем. В связи с этим в государственный стандарт введёна специальная
дисциплина “Теория алгоритмов”.
Дисциплина «Теория алгоритмов»
занимает важное место в теоретической информатике. В информатике выделяются
два направления – теоретическое и прикладное. Прикладная информатика
обеспечивает непосредственное создание информационных систем и программного
обеспечения для них, а также их применение для решения практических задач.
Теоретическая информатика - дисциплина, использующая методы математики.
Понятие алгоритма является центральным понятием теории алгоритмов и одним из
главных понятий математики. Зарождение и развитие теории алгоритмов связано с
фундаментальными достижениями выдающихся математиков: А.Тьюринга, А.Чёрча,
Э.Поста, А.А.Маркова, А.Н.Колмогорова, Ю.В. Матиясевича. Объектами ее изучения
являются: вопросы формализации понятия алгоритма, вопросы алгоритмически
неразрешимых проблем в математике и информатике, вопросы сложности алгоритма.
Основные задачи курса «Теория алгоритмов»:
1)
показать
взаимосвязь и взаимовлияние математики и информатики;
2)
познакомить с
основными подходами к формализации понятия алгоритма;
3)
познакомить с
основными идеями современной теории алгоритмов;
4)
сформировать у
студентов представление о теоретической базе программирования;
5)
сформировать
умения решения практических задач, требующих разработки алгоритмов и получения
точных результатов;
6)
развивать
алгоритмический и логический стили мышления.
1.2 Интуитивное понятие алгоритма. Исторический обзор.
Интуитивное представление о "вычислительной
процедуре" существовало у математиков уже давно, и за этими процедурами
был закреплен специальный термин, не отвечавший еще никакому точному понятию, -
алгоритм.
Слово "алгоритм" происходит от имени, работавшего
в IX в. в Багдаде (и писавшего, как все тогдашние мусульманские ученые,
по-арабски) математика аль-Хорезми (это имя указывает на происхождение из
Хорезма). В латинских переводах его сочинений, получивших распространение в
Европе с XII века, имя автора писалось в искаженной форме, чаще всего Algorithmus или Algorismus.. Со временем так
стали называть любую систему правил, позволяющих чисто механически выполнить
любую конкретную операцию некоторого определенного типа. Интуитивное понятие
алгоритма представляет его как строго сформулированное правило, задающее
последовательность выполнения конечного числа шагов, следуя которому можно
осуществить процесс решения задачи, причем осуществить механически, максимально
экономя усилия.
Алгоритм (алгорифм) -
способ (программа) решения вычислительных и других задач, точно
предписывающий, как и в какой последовательности получить результат,
однозначно определяемый исходными данными.
Алгоритм задается как предложение формального языка.
Алгоритмический язык
- это формализованный язык для однозначной записи алгоритмов.
Более сложные примеры: алгоритм Евклида, правило
Крамера для решения систем линейных уравнений, правила дифференцирования
элементарных функций и т.п.
Кроме алгоритмов для вычисления функции, говорят еще
об алгоритмах для распознавания свойств и отношений, подразумевая под этим
строго определенные "правила" или "процедуры", позволяющие
отвечать на вопросы вроде: "Является ли данное натуральное число
простым?", "Являются ли два данных натуральных числа взаимно простыми?"
и т.п. Однако задача распознавания свойства или отношения всегда может быть
представлена как задача нахождения, или "вычисления", поэтому под
алгоритмом всегда можно понимать процедуру, позволяющую "находить"
или "вычислять" значения некоторой функции.
Алгоритмы обладают следующими двумя характерными особенностями:
1)
Наличие четкого описания. Алгоритм
всегда описывается настолько четко, что на основе этого описания можно
действовать чисто механически, не вникая в смысл;
2)
Детерминированность. Это значит, что
если процедура является алгоритмом, то ни в какой момент ее выполнения не
должно возникать сомнения, что делать дальше: каждый следующий шаг должен однозначно
определяться исходными данными (т.е. значением аргумента) и результатами уже
выполненных шагов.
Рассмотрим некоторые основные принципы, по которым строятся алгоритмы, и выясним, что
же именно в понятии алгоритма нуждается в уточнении:
Первое, что следует
отметить в любом алгоритме – это то, что он применяется к исходным данным и
выдает результаты. В технических терминах это означает, что алгоритм имеет
входы и выходы.
Кроме того, в ходе работы алгоритма появляются
промежуточные результаты, которые используются в дальнейшем. Т.о. каждый
алгоритм имеет дело с данными – входными, промежуточными и выходными.
Термин "данные"
относится к формализованному представлению информации. Данные могут состоять из
файлов информационных записей в виде "битов" (единиц и нулей) или же
могут иметь форму одинаковым образом оцифрованной информации.
Поскольку мы собираемся уточнять понятие
алгоритма, нужно уточнить и понятие данных, то есть
указать, каким требованиям должны
удовлетворять объекты, чтобы алгоритм мог с ними работать. Ясно, что эти объекты должны быть четко
определены и отличимы как друг от друга,
так и от "необъектов".
Все данные до некоторой степени подвержены
воздействиям человеческой непоследовательности, вкрадываются ошибки.
В теории алгоритмов фиксируют конкретные конечные
наборы исходных объектов (называемые элементарными) и конечный набор средств
построения объектов из элементарных. Набор элементарных объектов образует
конечный алфавит исходных символов (цифр, букв, и т.д.) из которых строятся
другие объекты; типичным средством построения являются индуктивные определения, указывающие, как строить новые объекты из уже
построенных.
Например, в
программе «АЛГОЛ» определение идентификатора дано следующим образом: идентификатор – это либо
буква, либо идентификатор, к которому
приписана справа буква или цифра.
Слова
конечной длины (например, числа) –
наиболее обычный тип
алгоритмических данных, а число символов в слове – естественная единица
измерения объема обрабатываемой
информации. Более сложный
случай алгоритмических объектов – формулы.
Они также определяются индуктивно и также являются словами в конечном
алфавите, однако не каждое слово в этом
алфавите является формулой. В этом
случае перед основным алгоритмом идут вспомогательные, которые проверяют, удовлетворяют ли исходные данные нужным требованиям.
Такая проверка называется синтаксическим анализом.
Второе, данные для
своего размещения требуют памяти. Память обычно считается однородной и
дискретной, то есть состоит из одинаковых ячеек, причем каждая ячейка может
содержать один символ алфавита данных. Т.о. единицы измерения объема данных и
памяти согласованы. При этом память может быть бесконечной.
Третье, алгоритм состоит из отдельных элементарных
шагов, причем множество различных шагов, из которых составлен алгоритм –
конечно. Обычно элементарный шаг имеет дело с фиксированным числом символов, однако это требование не
всегда выполняется.
Четвертое,
последовательность шагов алгоритма детерминирована, т.е. после каждого шага
указывается, какой шаг делать дальше, либо дается команда останова, после чего работа алгоритма
считается законченной.
Пятое,
естественно для алгоритма потребовать результативности, т.е. остановки после
конечного числа шагов с указанием того, что считать результатом. Однако,
проверить результативность (сходимость) гораздо труднее, чем предыдущие
требования. Сходимость обычно не удается установить простым просмотром
алгоритма. Общего метода проверки сходимости пригодного для любого алгоритма и
любых данных вообще не существует.
Шестое, следует
различать следующие действия:
а. описание
алгоритма (программу);
б. механизм
реализации, включающий средства пуска,
останова, реализации элементарных шагов, выдачи результатов и обеспечения
управления ходом вычисления (ЭВМ);
в. процесс
реализации алгоритма, то есть последовательность шагов, которая будет
порождена при применении алгоритма к конкретным данным.
Например:
рассмотрим следующую задачу:
дана последовательность Р из n
положительных чисел ( n – конечное, но
произвольное число); требуется
упорядочить их, то есть построить последовательность R, в которой эти же числа
распололжены в порядке возрастания.
Простейший способ,
который приходит в голову: просматриваем Р и находим наименьшее число; вычеркиваем его из Р и
выписываем его как первое число R;
снова просматриваем Р и
находим наименьшее число,
приписываем его справа к R и т.д., пока
в Р не будут вычеркнуты все числа.
Возникает вопрос, что значит "и
т.д.". Перепишем описание в более
четкой форме, с указанием переходов между шагами.
Шаг 1. Ищем в Р наименьшее число.
Шаг 2. Найденное число записываем справа к R и
вычеркиваем из Р.
Шаг 3. Если в Р нет чисел, переходим к шагу 4, иначе
переходим к шагу 1.
Шаг 4. Конец. Результатом считать последовательность
R, построенную к этому моменту.
На вход подается информация или объект, подлежащий
обработке, а выходом является результат обработки или операции над входом.
Алгоритм есть процедура (или способ вычисления), осуществляемая черным ящиком
для получения выхода из входа.
Первым дошедшим до нас алгоритмом в его интуитивном понимании – конечной
последовательности элементарных действий, решающих поставленную задачу,
считается предложенный Евклидом в III веке до нашей эры алгоритм нахождения
наибольшего общего делителя двух чисел (алгоритм Евклида). Отметим, что в
течение длительного времени, вплоть до начала XX века само слово «алгоритм»
употреблялось в устойчивом сочетании «алгоритм Евклида». Для описания
пошагового решения других математических задач использовалось слово «метод».
Интуитивными представлениями алгоритма математики
могли обходиться до тех пор, пока речь шла только об отыскании алгоритмов для
решения конкретных "вычислительных" задач. При этом всякий раз нужный
алгоритм удавалось найти, потому что когда алгоритм найден, ни у кого из
математиков не возникает сомнения, что это действительно алгоритм, т.е.
вычислительная процедура. Но со временем возникли некоторые задачи, несомненно
"вычислительного" характера, все попытки нахождения алгоритмов для
которых заводили в тупик, и появилась гипотеза, что, по крайней мере, для части
этих задач вообще никаких алгоритмов не существует. Проверка этой гипотезы в
каждом случае требует уже строгого определения алгоритма: ведь если мы хотим
математически доказать, что чего-то не существует, это "что-то"
должно быть определено так, как полагается определять математические понятия.
Именно в связи с проблемой доказательства не существования
алгоритма в 30-е годы нынешнего столетия одновременно несколькими исследователями
- К. Гёделем, Э. Постом, А. Тьюрингом - были предприняты усилия дать точное
определение соответствующего понятия.
В результате этих усилий было предложено несколько
вариантов определения, которые оказались равносильными, и на их основе удалось
доказать, что для многих "вычислительных" задач алгоритмы действительно
невозможны. Вместе с тем благодаря наличию строгого определения математики
смогли заняться изучением общих свойств алгоритмов (или, что по существу то же
самое, "вычислимых" функций), их классификацией и т.п.
Начальной точкой отсчета современной теории алгоритмов можно считать работу
немецкого математика Курта Гёделя (1931 год - теорема о неполноте символических
логик), в которой было показано, что некоторые математические проблемы не могут
быть решены алгоритмами из некоторого класса. Общность результата Геделя
связана с тем, совпадает ли использованный им класс алгоритмов с классом всех
(в интуитивном смысле) алгоритмов. Эта работа дала толчок к поиску и анализу
различных формализаций алгоритма.
Первые фундаментальные работы по теории алгоритмов были опубликованы
независимо в 1936 году годы Аланом Тьюрингом, Алоизом Черчем и Эмилем Постом.
Предложенные ими машина Тьюринга, машина Поста и лямбда-исчисление Черча были
эквивалентными формализмами алгоритма. Сформулированные ими тезисы (Поста и
Черча-Тьюринга) постулировали эквивалентность предложенных ими формальных
систем и интуитивного понятия алгоритма. Важным развитием этих работ стала
формулировка и доказательство алгоритмически неразрешимых проблем.
В 1950-е годы существенный вклад в теорию алгоритмов внесли работы
Колмогорова и Маркова.
К 1960-70-ым годам оформились следующие направления в теории алгоритмов:
1)
Классическая
теория алгоритмов (формулировка задач в терминах формальных языков, понятие
задачи разрешения, введение сложностных классов, формулировка в 1965 году
Эдмондсом проблемы P=NP, открытие класса NP-полных задач и его исследование);
2)
Теория
асимптотического анализа алгоритмов (понятие сложности и трудоёмкости
алгоритма, критерии оценки алгоритмов, методы получения асимптотических оценок,
в частности для рекурсивных алгоритмов, асимптотический анализ трудоемкости или
времени выполнения), в развитие которой внесли существенный вклад Кнут, Ахо,
Хопкрофт, Ульман, Карп;
3)
Теория
практического анализа вычислительных алгоритмов (получение явных функции
трудоёмкости, интервальный анализ функций, практические критерии качества
алгоритмов, методика выбора рациональных алгоритмов), основополагающей работой
в этом направлении, очевидно, следует считать фундаментальный труд Д. Кнута
«Искусство программирования для ЭВМ».
1.3 Практическое применение результатов теории
алгоритмов
Полученные в теории алгоритмов теоретические результаты находят достаточно
широкое практическое применение, при этом можно выделить следующие два аспекта:
1) Теоретический аспект: при исследовании некоторой задачи результаты теории
алгоритмов позволяют ответить на вопрос – является ли эта задача в принципе
алгоритмически разрешимой – для алгоритмически неразрешимых задач возможно их
сведение к задаче останова машины Тьюринга. В случае алгоритмической
разрешимости задачи – следующий важный теоретический вопрос – это вопрос о
принадлежности этой задачи к классу NP–полных задач, при утвердительном ответе
на который, можно говорить о существенных временных затратах для получения
точного решения для больших размерностей исходных данных.
2) Практический аспект: методы и методики теории
алгоритмов (в основном разделов асимптотического и практического анализа)
позволяют осуществить:
а.
рациональный
выбор из известного множества алгоритмов решения данной задачи с учетом
особенностей их применения (например, при ограничениях на размерность исходных
данных или объема дополнительной памяти);
б.
получение
временных оценок решения сложных задач;
в.
получение
достоверных оценок невозможности решения некоторой задачи за определенное
время, что важно для криптографических методов;
г.
разработку и
совершенствование эффективных алгоритмов решения задач в области обработки
информации на основе практического анализа.
1.4 Формализация понятия алгоритма.
Во всех сферах своей деятельности, и частности в сфере обработки
информации, человек сталкивается с различными способами или методиками решения
задач. Они определяют порядок выполнения действий для получения желаемого
результата – это трактуется как
первоначальное или интуитивное определение алгоритма. Некоторые дополнительные
требования приводят к неформальному определению алгоритма:
Определение 1.1 Алгоритм - это заданное на некотором языке конечное предписание, задающее конечную
последовательность выполнимых элементарных операций для решения задачи, общее
для класса возможных исходных данных.
Пусть D – область (множество) исходных данных задачи, а R – множество
возможных результатов, тогда мы можем говорить, что алгоритм осуществляет
отображение D --> R. Поскольку такое отображение может быть не полным, то
вводятся следующие понятия:
Алгоритм называется частичным алгоритмом, если мы получаем результат только
для некоторых d є D и полным алгоритмом, если алгоритм получает правильный
результат для всех d є D.
Несмотря на усилия исследователей, отсутствует одно исчерпывающе строгое
определение понятия алгоритм, в теории алгоритмов были введены различные
формальные определения алгоритма и удивительным научным результатом является
доказательство эквивалентности этих формальных определений в смысле их
равномощности.
Варианты словесного определения алгоритма принадлежат российским ученым
А.Н. Колмогорову и А.А. Маркову
Определение 1.2 (по А.Н. Колмогорову): Алгоритм – это всякая система вычислений,
выполняемых по строго определенным правилам, которая после какого-либо числа
шагов заведомо приводит к решению поставленной задачи.
Определение 1.3 (по А.А. Маркову): Алгоритм – это точное предписание,
определяющее вычислительный процесс, идущий от варьируемых исходных данных к
искомому результату.
Отметим, что различные определения алгоритма, в
явной или неявной форме, постулируют следующий ряд требований:
1)
алгоритм должен
содержать конечное количество элементарно выполнимых предписаний, т.е.
удовлетворять требованию конечности записи;
2)
алгоритм должен
выполнять конечное количество шагов при решении задачи, т.е. удовлетворять
требованию конечности действий;
3)
алгоритм должен
быть единым для всех допустимых исходных данных, т.е. удовлетворять требованию
универсальности;
4)
алгоритм должен
приводить к правильному по отношению к поставленной задаче решению, т.е.
удовлетворять требованию правильности.
Другие формальные определения понятия алгоритма связаны с введением
специальных математических конструкций (машина Поста, машина Тьюринга,
рекурсивно-вычислимые функции Черча) и постулированием тезиса об
эквивалентности такого формализма и понятия «алгоритм».
Признаки, присущие алгоритмам:
1) алгоритм есть совокупность инструкций, имеющих
конечную длину (эта длина измеряется, например, числом символов, необходимых
для записи правил);
2) имеется механизм (человек, механическое,
оптическое и т.п. устройство, электронная машина), воспринимающий и выполняющий
инструкции;
3) имеются средства (человеческая память, карандаш и
бумага, зубчатые колеса, магнитные запоминающие устройства и т.п.), позволяющие
фиксировать и хранить сведения о любых этапах работы по выполнению инструкций,
а также выдавать эти сведения по мере необходимости;
4) существенно, что все выполняемые процедуры
являются дискретными (хотя обрабатываемые ими объекты могут быть по своему
характеру непрерывными);
5) последовательность элементарных операций, из
которых складываются инструкции, жестко определена (как обычно говорят, детерминирована):
на каждом шаге процесса переход к следующему шагу возможен не более чем одним
способом.
Здесь прослеживается аналогия с парой
(вычислительная машина, программа), а именно:
а) соответствует программе;
6) соответствует вычислительной машине, работающей
по этой программе;
в) соответствует машинной памяти;
г) соответствует дискретной ("цифровой")
природе цифровых вычислительных машин (в отличие от аналоговых);
д) соответствует механичности и жесткой
детерминированности порядка выполнения команд программы.
На вход подается информация или объект, подлежащий
обработке, , а выходом является результат обработки или операции над входом.
Выход вырабатывается автоматически черным ящиком, который может быть
компьютером или школьником, действующим по инструкции. Алгоритм есть процедура
(или способ вычисления), осуществляемая черным ящиком для получения выхода из
входа.
Тема 2. Вычислимые функции
2.1 Понятие разрешающей процедуры и вычислимой функции.
Рассмотрим некоторый данный счетно-бесконечный класс
математических или логических вопросов, каждый из которых требует ответа
"да" или "нет". Существует ли метод (процедура), с помощью
которого можно ответить на любой вопрос из этого класса за конечное число
шагов?
Более подробно поинтересуемся тем, можно ли для
данного класса вопросов раз и навсегда описать процедуру или перечислить набор
правил (предписаний), который можно было бы использовать следующим образом.
Если (после того, как процедура описана) возьмем любой вопрос из данного
класса, то процедура скажет, как выполнить последовательные шаги, после
конечного числа которых, получим ответ на рассматриваемый вопрос. При
выполнении шагов пользователям придется только механически следовать
предписаниям, как если бы они были роботами: не потребуется ни понимания, ни
искусства, ни изобретательности. После каждого шага, если еще не получен
окончательный ответ, предписания в сочетании с имеющейся ситуацией подскажут,
что делать дальше. Предписания позволят нам узнать, когда последовательность
шагов заканчивается, и "считать" с получившейся в конце ситуации
ответ на рассматриваемый вопрос: "да" или "нет"?
Поскольку никакой человек-исполнитель не может
использовать более чем конечное количество информации, описание процедуры с
помощью списка правил или предписаний должно быть конечным.
Если такая процедура существует, она называется разрешающей процедурой, или разрешающим алгоритмом для данного
класса вопросов. Проблема разыскания разрешающей процедуры называется проблемой разрешения для этого класса.
Возвращаясь к случаю алгоритмов для
счетно-бесконечных классов вопросов, заметим, что и они подобным же образом
всегда существовали бы с классической точки зрения, если бы мы допустили, чтобы
алгоритмы (описания алгоритмов) были бесконечными объектами; мы опять могли бы
просто перечислить все ответы. Но нами было сказано, что алгоритм должен быть
методом (процедурой, набором правил), который может быть использован и который,
следовательно, должен быть описан конечным образом. Должен быть дан конечный
набор предписаний, достаточный, чтобы прийти к ответу на любой из бесконечного
множества вопросов.
Поскольку наш класс вопросов всегда
счетно-бесконечен, мы всегда можем перечислить все эти вопросы, скажем, в виде Q1, Q2, Qa,...Тогда
переменной, или параметром, может быть а. В случае вопросов типа "да или
нет?", полагая Р(а)= {ответ на
вопрос Qa есть "да"}, мы превратим
бесконечный класс вопросов типа "да или нет?" в одноместный
теоретико-числовой предикат Р(а).
Предикат
(лат. praedicatum- заявленное,
упомянутое, сказанное) – это то, что утверждается о субъекте. Субъектом высказывания называется то, о
чем делается утверждение.
Предикат(n-местный и n-арный) – это функция с множеством значений
{0,1} (или «ложь» и «истина»).
Предположим теперь, напротив, что рассматриваемые
вопросы -это вопросы типа "чему равно?". Допустим далее, что объекты,
которые должны быть предъявлены в ответах на вопросы, берутся из некоторого
счетно-бесконечного класса, который мы можем перечислить в виде y1, y2,..., yb.
Полагая f(a) = b
, если ответ на вопрос Qa есть yb,
мы превратим бесконечный класс вопросов типа "чему равно?" в
одноместную теоретико-числовую функцию f(a).
Обратно, отправляясь от произвольного
теоретико-числового предиката Р(а1,...,аn) , мы получаем
счетно-бесконечный класс вопросов: "Для данных а1,...,аn истинно ли Р(а1,...,аn)? Отправляясь от
произвольной теоретико-числовой функции f(а1,...,аn), мы получаем вопросы:
"Для данных а1,...,аnчему равно значение f(а1,...,аn).
Таким образом, не имеет значения, говорим ли мы о
счетно-бесконечных классах вопросов или о теоретико-числовых предикатах и функциях.
Если для предиката (или для получающегося из него класса вопросов) существует
разрешающая процедура, мы называем этот предикат (или класс вопросов) разрешимым. Подобным образом,если для
некоторой функции имеется процедура вычисления, мы называем эту функцию вычислимой.
Вычислимая
функция – функция f(x), для которой существует алгоритм оценки для
любого элемента х в области
определения f(x).
Осознание того, что для некоторых
(счетно-бесконечных) классов математических вопросов у нас имеются алгоритмы, а
для других они нам, по меньшей мере, неизвестны, относится к далекому прошлому
математической истории. Греки, включая Евклида, искали алгоритмы. Напомним, что
все проблемы вычисления и разрешения, как мы видели, могут быть сведены к
проблемам вычисления для теоретико-числовых функций. Поэтому, чтобы
продвинуться к нашей цели (к теореме Чёрча), нам нужно будет заняться вопросом:
для каких теоретико-числовых функций имеются вычисляющие их процедуры
(алгоритмы), т.е. каков класс "вычислимых" функций?
Для дальнейшего рассмотрения этого вопроса мы
располагаем несколько расплывчатым интуитивным представлением о том, что
представляет собой вычислительная процедура. Вычислительная процедура может
состоять просто в прямом применении определения функции или в чем-то совсем
ином, что, как показывает математическая теория, должно вести к тем же
значениям функции, которых требует исходное определение.
Хотя наше интуитивное понятие вычислительной
процедуры расплывчато, оно, тем не менее, реально, как показывают следующие два
обстоятельства.
Во-первых,
оно не оставляет у математиков никаких сомнений и не приводит их ни к каким
расхождениям в вопросе о том, что они располагают вычислительными процедурами для многих аиbконкретных функций, например а+1, a+b, a*b, аb, max(a,b),min(a,b).
Во-вторых,
подобным же образом в других частных случаях нет сомнения в том, что
определение некоторой функции или данный эквивалент ее определения не
позволяет непосредственно указать вычислительную процедуру. Например, мы
согласны с тем, что представленное выше определение функции f(a) не дает для нее
вычислительной процедуры.
Это интуитивное понятие вычислительной процедуры,
которое достаточно реально, чтобы отделить те многие случаи, когда мы знаем,
что имеем перед глазами вычислительную процедуру, от многих других случаев,
когда мы знаем, что такой процедуры у нас нет, оказывается, однако,
расплывчатым, когда мы пытаемся извлечь из него картину совокупности всех
возможных вычислимых функций. А нам необходимо иметь такую картину, описанную в
точных терминах, прежде чем мы сможем доказать, что для некоторой конкретной
функции вообще не существует процедуры вычисления, или, короче, доказать, что
некоторая функция не вычислима.
Начиная с этого места, мы будем иногда говорить, что
нечто может быть сделано "эффективно" или, что некоторая операция или
процесс "эффективны", чтобы кратко выразить тот факт, что для этого
имеется алгоритм (т.е. разрешающая или вычислительная процедура).
В связи с этим приведем строгие определения.
Последовательность преобразований для заданного
элемента, позволяющая достичь заданной цели преобразований за конечное число
шагов, называется эффективным процессом.
Описание
эффективного процесса - это описание, содержащее следующие
условия: допустимость заданного элемента для данного процесса, описание
преобразования и его результата, условие достижения цели.
Обычно предписание определяет эффективный процесс
одновременно для многих элементов, т.е. процесс определен в общих терминах,
включающих параметры.
Эффективная
процедура - алгоритм, удовлетворяющий следующим требованиям:
1) должен состоять из конечного множества простых
(элементарных) команд, порядок исполнения которых должен быть однозначно задан;
2) при задании на вход алгоритма набора значений х из области определения f(x) вычисления
должны закончиться после конечного числа шагов и выдать соответствующее
значение f(x), а если набор
значений х не принадлежит области определения f(x), то вычисления
не приводят ни к какому результату.
2.2 Формальная теория вычислимости.
Первоначальной целью теории вычислимости (рекурсии)
было придать строгость интуитивной идее вычислимой функции, т.е. функции,
значения которой могут быть вычислены или автоматически или каким-либо другим
эффективным способом.
Рекурсивные функции уже в силу характера своего
определения оказываются вычислимыми, т.к. каждая рекурсивная функция задается
конечной системой равенств точно охарактеризованного типа в том смысле, что ее
значения вычисляются с помощью этой системы равенств по точно формулируемым правилам.
Это осуществляется таким образом, что в итоге для вычисления значений заданной
рекурсивной функции получается алгоритм определенного типа.
Очевидно, что к вычислимым функциям следует отнести
все константы, т.е. все натуральные числа 0,1,2,… . Нет необходимости включать
в базис бесконечное множество констант. Достаточно 0 и функции следования f(x) = x+1
(x’).
Кроме того в базис включается семейство функций
тождества ( или введения фиктивных переменных).
Inm (x1,…,xn)
= xm (m<=n),
где xот 1 доn.
Мощным средством получения новых функций из уже
имеющихся функций является суперпозиция.
Оператором суперпозиции называется подстановка Snm(h,g1,…,gm) =
h(g1(x1,…,xn)…,gm(x1,…,xn)).
Если заданы функция Inm и
операторы Snm,
то можно считать заданными всевозможные операторы подстановки функций в
функции, а так же переименования, перестановки и отождествления переменных.
Оператором
примитивной рекурсии Rn называются
подстановки, удовлетворяющие системе уравнений:
f(x1,…,xn )= g(x1,…,xn
),
f(x1,…,xn , y+1)= h(x1,…,xn
,y,f(x1,…,xn,y)),
которая называется схемой примитивной рекурсии.
Функция называется примитивно-рекурсивной, если она может быть получена из константы
0, функция следования и функция Inmс
помощью конечного числа применений операторов суперпозиции Snmи
примитивной рекурсии Rn.
В формально-индуктивном виде это определение
выглядит следующим образом:
1.
Функция 0,X’, Inm
для всех натуральных m и n являются примитивно-рекурсивными.
2.
Если h,g1,…gm-
примитивно-рекурсивные функции, то Snm-
примитивно-рекурсивная функция.
3.
Если g(x1,…,xn),h(x1,…,xm,y,z), - примитивно-рекурсивные
функции, то Rn-
примитивно-рекурсивная функция.
4.
Других примитивно-рекурсивных функций
нет.
Примерами
примитивно-рекурсивных функций являются:
1.
f(x, y)=x+y.
2.
f(x, y)=x*y.
3.
fexp(x, y)=xy.
Отношение R(x1,…,xn)называется примитивно-рекурсивным (ПР), если
примитивно-рекурсивна его характеристическая функция
XR(x1,…,xn) = {1, если R(x1,…,xn)- выполняется;0 –если не
выполняется
Оператор называется примитивно-рекурсивным (ПР), если он сохраняет примитивную
рекурсивность функций, т.е. если результат его применения дает снова
примитивно-рекурсивную функцию.
Еще один ПР-оператор
– оператор условного переходаB, который по функциям g1(x1,…,xn), и g2(x1,…,xn), и предикату P(x1,…,xn), строит функцию f(x1,…,xn) =B(g1,g2,P).
Ограниченный
оператор минимизации – применяется к предикатам.
Подведем некоторые
итоги. Из простейших функций - константы 0, функции следования и функций
тождества с помощью операторов суперпозиции и примитивной рекурсии может быть
получено огромное разнообразие функций, включающих основные функции арифметики,
алгебры и анализа (с поправкой на целочисленность). Следует сделать два
замечания
1. Все примитивно-рекурсивные функции всюду
определены. Это следует из того, что простейшие функции всюду определены, а Snm и Rn- это свойство сохраняют.
2. Строго говоря, мы имеем дело не с
функциями, а с их примитивно-рекурсивным описанием. Различие здесь имеет тот же
смысл, что и различие между функциями и их представлением в виде формул.
Все ли функции
являются примитивно-рекурсивными? Простые теоретико-множественные соображения
показывают, что нет.
Функция называется частично-рекурсивной, если она может
быть построена из простейших функций: 0, х’,
Inm с помощью конечного числа применений Snm, Rn и -оператора.
Среди рекурсивных
функций появляются не полностью определенные, т.е. частичные функции. Операторы над частичными функциями порождают
новые частичные функции. При этом характер неопределенности может оказаться
довольно сложным, а именно: для данного набора не найдется способа установить
определена ли она на этом наборе и придется продолжать процесс вычисления
неопределенное время, не зная, остановится он или нет. Частично-рекурсивная
функция называется общерекурсивной,
если она всюду определена.
Модуль II. Машина Тьюринга.
Тема 3. Вычислимость по Тьюрингу.
3.1 Машина Тьюринга: определение, механизм работы.
Концепция
абстрактной вычислительной машины была предложена еще в 1936 г. (т.е. до
создания первых электронных вычислительных машин) английским математиком и
логиком Аланом Тьюрингом. Он показал возможность существования универсальной
вычислительной машины (машины Тьюринга), способной выполнить любую эффективную
процедуру.
Понятие
машины Тьюринга возникло в результате прямой попытки разложить известные нам
вычислительные процедуры на элементарные операции. Тьюринг привел ряд доводов в
пользу того, что повторения его элементарных операций было бы достаточно для
проведения любого возможного вычисления.
Машина
Тьюринга - это гипотетическая вычислительная машина (автомат),
использовавшаяся в качестве математической абстракции А. Тьюрингом с целью
уточнения эффективного процесса (алгоритма) вычислений.
Если
говорить об абстрактной схеме построения машины Тьюринга, то она представляет
собой хорошую математическую модель электронно-вычислительной
машины.
До
сих пор все вычислительные машины в некотором смысле базируются на идее
Тьюринга: их память физически состоит из битов, каждый из которых содержит либо
0 либо 1. Более того, т.н. микропрограммное управление унаследовало от этих
абстрактных машин и программу, помещенную в "постоянную память", и в
значительной мере структуру команды.
Как
и арифметическое устройство ЭВМ, машина Тьюринга имеет конечное число
внутренних состояний. Ее поведение в каждый данный момент зависит от состояния,
в котором она находится, и от того символа, который она получает в качестве
внешней информации. Если отвлечься от того, что процесс ввода информации
идеализирован и сведен к чтению одного атомарного символа на каждом шаге, то
поведение машины Тьюринга не отличается от функционирования реальной ЭВМ.
Машина
Тьюринга представляет собой автомат, с конечным числом состояний, соединенный с
внешней памятью – лентой, разбитой на ячейки, в каждой из которых записан один
из символов конечного алфавита А= { a1, ... am}.
Автомат
связан с лентой с помощью головки, которая в каждый момент времени обозревает
одну ячейку ленты, и в зависимости от символа в этой ячейке и состояния
управляющего устройства записывает в ячейку символ (совпадающий с прежним или
пустой), сдвигается на ячейку вправо или влево или остается на месте. Среди
состояний управляющего устройства выделим начальное состояние q1 и заключительное состояние qz. В начальном состоянии машина находится
перед началом работы. Попав в заключительное состояние, машина
останавливается. Т.о. память машины Т – это конечное множество
состояний (внутренняя память) и лента (внешняя память). Лента бесконечна в обе
стороны, однако в любой момент времени лишь конечный отрезок ленты будет
заполнен символами. Поэтому важна не фактическая бесконечность ленты, а ее
неограниченность, т.е. возможность писать на ней сколь угодно длинные, но
конечные слова.
Данные в машине Т–
это слова в алфавите ленты; на ленте записываются и исходные данные и
окончательные результаты. Элементарные шаги – это считывание и запись символов,
сдвиг головки на ячейку влево или вправо, а также переход управляющего
устройства в следующее состояние.
Детерминированность
машины Т определяется следующим образом: для любого внутреннего состояния qi и символа aj однозначно
заданы
а)
следующее состояние qi`
б)
символ aj`, который надо
записать в ту же ячейку вместо aj(стирание
– это запись пустого символаW)
в)
направление сдвига головки dk (L – влево, R – вправо, E – на
месте).
Это
задание может описываться либо системой правил
qi aj qi` aj` dk
-
либо таблицей,
строкам которой соответствуют состояния, столбцам – входные символы, а на
пересечении записана тройка символов qi` aj` dk.
-
либо блок-схемой
(диаграммой переходов), в которой состояниям соответствуют вершины, а
правилу вида (qi aj qi` aj` dk) – ребро, ведущее из qi в qi` .
Полное
состояние машины Т, по которому однозначно
можно определить ее дальнейшее поведение, определяется ее внутренним состоянием, состоянием ленты
(т.е. символом, записанным на ленте) и положением головки на ленте.
Полное состояние машины Т будем называть конфигурацией или машинным словом. Стандартной
начальной конфигурацией называется конфигурация вида q1, то есть конфигурацию, содержащую начальное состояние, в
котором головка обозревает крайний левый символ слова, написанного на ленте.
Аналогично, стандартной заключительной конфигурацией называется конфигурация
вида qz . Ко всякой не заключительной конфигурации К машины Т применима ровно одна команда вида:
qi aj qi’ aj’ dk,
которая конфигурацию К переводит в конфигурацию К’.
Последовательность
К1 К2 К3 ... однозначно определяется исходной конфигурацией К1и полностью описывает работу машины Т, начиная с К1.
Для
того чтобы говорить о том, что могут делать машины Т, уточним как будет интерпретироваться их поведение и как будут
представляться данные.
Исходными
данными машины Т будем считать записанные на ленте слова в
алфавите исходных данных и векторы из таких слов. Для любого набора V над Аисх машина Т
либо работает бесконечно, либо перерабатывает его в совокупность слов в
алфавите результатов (Аисх и Арез могут
пересекаться и даже совпадать).
Пусть
f – функция, отображающая множество
векторов над Аисх в множество векторов над Арез.
Машина Т правильно вычисляет функцию f , если
1) для любых V и W таких, что f(V)=W q1V*
q1zW* , где V*
и W*– правильные записи V, W.
2)
для любого V такого, что f(V) не определена, машина Т, запущенная в стандартной начальной
конфигурации q1V*, работает бесконечно долго.
Если
для f существует машина Т, которая ее правильно вычисляет, f называется правильно вычислимой по Тьюрингу. С другой стороны, любой правильно
вычисляющей машине Т можно поставить
в соответствие вычисляемую ею функцию.
Пусть f() задана описанием: "если P() истинно, то f()=g1(), иначе f()=g2()". Функция называется разветвлением или условным
переходом к g1() и g2() по условию P().
Благодаря
вычислимости композиции и разветвления словесные описания и язык блок-схем
можно сделать вполне точным языком для описания работы машин Тьюринга.
3.2 Компоненты машины Тьюринга. Тезис Тьюринга.
С точки зрения формального описания машина Тьюринга
есть совокупность следующих пяти компонентов:
1) управляющего устройства, способного принимать
некоторое число состояний, которые соответствуют различным комбинациям
состояний внутренних элементов электронной машины (ячейки памяти, электронные
схемы и т.п.);
2) ленты, разделенной на конечное число ячеек (-1).
На ленте выбрано направление, называемое направлением слева направо. Соответственно
этому, на ленте выделяются крайняя слева и крайняя справа ячейки (в частном
случае, когда лента состоит из одной ячейки, они совпадают); каждая ячейка,
кроме крайней слева, имеет единственную соседнюю слева, каждая, кроме крайней
справа, имеет единственную соседнюю справа. В процессе работы машины лента
может изменяться, а именно, к ней могут подклеиваться новые ячейки справа,
т.е. число ячеек предполагается неограниченным в обе стороны;
3) головки, которая в каждый момент работы машины
находится в некоторой ячейке ленты и считывает информацию из этой ячейки.
Головка может работать в каждый момент только с одной ячейкой ленты. При этом
она может заменять прочитанный символ другим символом;
4) двух конечных алфавитов – внешнего и внутреннего,
называемого также множеством состояний. Внешний алфавит - это конечный алфавит
символов, которые подаются на вход машины Тьюринга и выдаются на ее выходе. Внутренний
алфавит - это конечный алфавит символов, комбинации которых определяют
внутреннее состояние машины Тьюринга.
Элементы £ называются внешними символами
машины, элементы S
- внутренними состояниями или просто состояниями. В каждый момент работы машина
находится в некотором состоянии (т.е. ей сопоставлен некоторый элемент
алфавита S)
и в каждой ячейке ленты записан некоторый (единственный) внешний символ. Таким
образом, внешние символы видны на ленте, являющейся внешним устройством машины,
в то время как состояние не видно и является в каждый момент чем-то внутренне
присущим машине в целом.
Систему
команд машин Тьюринга можно интерпретировать и как описание работы конкретного
механизма и как программу. Естественно поставить задачу построения машины
Тьюринга, реализующей алгоритм воспроизведения работы машины Тьюринга – такая
машина называется универсальной. Существование универсальной машины Тьюринга
означает, что систему команд любой машины Тьюринга можно представить двояко:
либо как описание работы конкретного устройства машины Т, либо как программу для универсальной машины U. Это естественно: для инженера, проектирующего систему
управления, любой алгоритм управления может быть реализован либо аппаратурно –
построением соответствующей схемы, либо программно – написанием программы для
универсальной управляющей ЭВМ.
Такая
интерпретация на абстрактном уровне сохраняет основные плюсы и минусы
инженерной реализации: конкретная машина Т
работает гораздо быстрее; управляющее устройство U довольно громоздко, однако
его величина постоянна и, будучи раз построено, оно годится для реализации
сколь угодно больших алгоритмов. Кроме того при смене алгоритма не понадобится
строить новых устройств, нужно будет лишь написать новую программу.
Тезис Тьюринга:
Всякий алгоритм может быть реализован машиной Тьюринга.
Доказать
тезис нельзя, поскольку само понятие алгоритма является неточным.
Подтверждением тезиса являются:
-
во-первых,
математическая практика,
-
во-вторых, то, что
описание алгоритма в терминах любой другой известной алгоритмической модели
может быть сведено к его описанию в виде машины Тьюринга.
В
числе общих требований, предъявляемых к алгоритмам, упоминалось требование
результативности. В наиболее радикальном виде: по любому алгоритму А и данным определить, приведет ли работа А при исходных данных к результату или нет. Иначе говоря, нужно построить
алгоритм В такой, что В(А,)=И, если А() дает результат, и
В(А,)=Л, если нет.
В
силу тезиса Тьюринга эту задачу можно сформулировать как задачу о построении
машины Тьюринга. Эта задача называется проблемой остановки.
Теорема:
Не существует машины Тьюринга, решающей проблему остановки для произвольной
машины Тьюринга.
Эта
теорема дает первый пример алгоритмически неразрешимой проблемы. Следует иметь
в виду, что речь идет об отсутствии единого
алгоритма, решающего данную проблему, при этом не исключается возможность
решения в частном случае. И неразрешимость общей проблемы остановки не снимает
необходимости доказывать сходимость предлагаемых алгоритмов.
Тема 4. Тезис Черча
4.1 Тезис Черча и его значимость. Элементарные шаги
Тезис Черча важен для приложений математики в
естествознание. При этом необходимо отметить, что тезис Черча не является математическим
утверждением, так как в его формулировку входит понятие алгоритма в интуитивном
смысле этого слова.
Тезис Черча:
всякая эффективно вычислимая функция является вычислимой по Тьюрингу. Другими
словами, для всякой функции, которую можно каким-либо способом вычислить, можно
построить вычисляющую ее машину Тьюринга. Это утверждение, называемое обычно
тезисом Черча -Тьюринга, впервые было высказано А. Тьюрингом в 1936 г.
применительно к конструкции машины. Аналогичное утверждение применительно к
некоторому совсем другому уточнению того же интуитивного понятия было несколько
раньше высказано А. Черчем.
По своему статусу этот тезис похож скорее на
законы физики, представляющие собой обычно утверждения о том, что то или иное
явление природы описывается некоторой математической конструкцией (например,
дифференциальным уравнением) - с той разницей, что речь идет не о явлении
природы, а об одном из видов человеческой деятельности - вычислении. В
справедливости физических законов мы убеждаемся путем анализа опытных данных;
аналогичным образом к убеждению в справедливости тезиса Черча-Тьюринга приводит
нас анализ фактов, относящихся к вычислительной практике и смежным с ней
областям.
Обратимся, прежде всего, к вычислению, выполняемому
человеком без использования вспомогательных средств. Слово
"вычисление" следует понимать
в широком смысле - не обязательно как оперирование с числами. Примерами
"нечисловых вычислений" могут служить тождественные преобразования в
элементарной алгебре или в логике предложений, нахождение производных от
элементарных функций и т.п. Каждое вычисление состоит в последовательном
преобразовании некоторого комплекса символов, записанных на бумаге или на
доске. (Вычисления "в уме" можно не рассматривать, так как их всегда
можно заменить письменными вычислениями, имеющими ту же структуру.)
Принципиально ничего не изменится, если мы будем представлять себе, что всякое
вычисление производится на одной достаточно большой доске (доска отличается от
бумаги тем, что написанное на ней можно стирать и на освободившемся месте
писать снова) и что доска разграфлена на клетки, причем в каждой клетке можно
записать только один символ. Вычисление можно теперь рассматривать как
последовательность шагов, на каждом из которых изменяется содержимое одной
клетки; в общем случае это означает, что записанный в клетке символ стирается и
на его месте записывается другой. Но от чего зависит, в какой клетке
производится очередной шаг и что в ней на этом шаге записывается? Разумеется,
не только от того, что было раньше записано в ней самой, но и от содержимого
других клеток; например, при сложении "столбиком" записываемая в
клетке цифра определяется цифрами, стоящими над ней. Следовательно, прежде чем
изменить содержимое какой-либо клетки, нужно, вообще говоря, просмотреть
некоторые другие клетки и запомнить какие-то сведения о том, что в них
находится. Кроме того, следующий шаг может зависеть от предыдущих; поэтому
после выполнения очередного шага бывает нужно что-то о нем запомнить.
Мы можем сказать теперь, что кроме "явных"
шагов, на которых изменяется содержимое клеток, имеются еще
"неявные", состоящие в просмотре клеток без изменения их содержимого.
Но между этими двумя типами шагов нет принципиальной разницы, так как просмотр
клетки можно представлять себе как "нулевое изменение":
записываемый в клетке символ совпадает с находившимся там ранее. Таким образом,
вычисление состоит из "элементарных шагов", на каждом из которых
изменяется содержимое какой-то клетки, и о всяком шаге вычислитель должен,
вообще говоря, что-то запомнить. В любой момент он держит в памяти какие-то
сведения об уже выполненной части вычисления. После очередного шага к этим
сведениям что-то добавляется и вместе с тем что-то из имевшихся ранее сведений
может быть на данном шаге "использовано до конца" и за ненужностью
забыто; естественно сказать, что при каждом шаге "состояние памяти"
изменяется. Это "состояние памяти" можно представлять себе как набор
сведений о некоторых уже выполненных шагах, причем для каждого шага указываются,
скажем, координаты клетки, где он выполняется, характер изменения содержимого и
"давность" этого шага по отношению к настоящему моменту. Все эти или
любые другие сведения о выполненных шагах можно записать в виде некоторого
слова в конечном алфавите (для данного вычисления фиксированном). Но объем
памяти человека ограничен: существует константа (сейчас нам неважно, какая),
ограничивающая сверху длины запоминаемых слов. Поэтому число возможных
"состояний памяти" конечно.
Заметим теперь, что в отличие от "явных
шагов", с которых мы начинали анализ процесса вычисления, каждый
"элементарный шаг" зависит только от состояния памяти и от
содержимого той клетки, где в этот шаг выполняется (результаты просмотра других
клеток учитываются в состоянии памяти). На каждом "элементарном шаге"
изменяются содержимое одной клетки и состояние памяти (разумеется, изменение
состояния памяти также может быть нулевым). Кроме того, каждый предыдущий
"элементарный шаг" должен включать в себя указание "адреса"
клетки, где нужно произвести следующий. Не будет существенным ограничением
считать то, что эта новая клетка, если она не совпадает со старой, расположена
рядом с ней - ведь до любой клетки можно дойти "мелкими шажками",
сдвигаясь каждый раз на одну клетку (вправо, влево, вверх или вниз).
Итак, мы расчленили процесс вычисления на
"элементарные шаги", каждый из которых состоит в том, что
"вычислитель", обозревая некоторую клетку и учитывая, каково
состояние его памяти и что записано в обозреваемой клетке, производит три
операции:
1) заменяет символ, записанный в обозреваемой
клетке, другим символом;
2) переходит к обозрению одной из четырех соседних
клеток или продолжает обозревать ту же клетку;
3) изменяет состояние памяти. Такой шаг может быть
выполнен часто механически, без понимания его смысла, если имеется инструкция -
при таком-то состоянии памяти и таком-то символе в обозреваемой клетке заменить
этот символ на такой-то, сдвинуться в такую-то сторону (или не сдвигаться) и
заменить состояние памяти на такое-то. Эта инструкция может быть, очевидно,
записана в точно такой же форме, в какой записываются команды машины Тьюринга:
qa
—>a'Cq',
где q
и q'
- состояния памяти,
а' - символы, используемые при вычислении,
С - принимает одно из значений "вправо",
"влево", "вверх", "вниз", "на месте".
Итак, анализ процесса вычисления приводит к "двумерной
машине Тьюринга", отличающейся от рассмотренной одномерной только
тем, что лента заменена разграфленной на клетки доской и головка движется не в
двух, а в четырех направлениях. Такая двумерная машина вполне могла бы
использоваться в качестве уточнения понятия алгоритма. Но одномерная машина
"технически проще" и поэтому удобнее для формальной трактовки (т.е.
для доказательства теорем и т.п.), хотя принципиальной разницы между одномерным
и двумерным вариантами нет (клетки, на которые разграфлена доска, можно тем или
иным регулярным способом расположить на одномерной ленте). При этом, клетки,
соседние на доске, не обязательно будут соседними на ленте, но всегда можно "найти"
на ленте клетку, которая на доске была рядом с обозреваемой, с помощью
некоторой "стандартной подпрограммы".
Таким образом, анализ того, как вычисляет человек,
подтверждает тезис Черча. Применение вспомогательных средств (например, таблиц)
или механических приспособлений (счеты, арифмометр) не дает ничего
принципиально нового: использование таблиц всего лишь увеличивает объем памяти
вычислителя (что может быть очень важно практически, но теоретического значения
не имеет), а вычисления с помощью простых механизмов можно
"моделировать" последовательными изменениями их (механизмов) схем,
выполненных с помощью символов на клетчатой доске.
4.2 Вычисления с помощью современных вычислительных машин.
Что касается вычислений с помощью современных
вычислительных машин с программным управлением, то и их принципиальные
возможности, как известно, не превышают возможностей человека-вычислителя
(единственное их преимущество - быстродействие). Кроме того, читатель, хотя бы
немного знакомый с этими машинами, наверняка сразу заметил, что машины Тьюринга
очень на них похожи, и построение машин Тьюринга для вычисления конкретных
функций - это, в сущности, программирование (в отличие от программы для ЭВМ
программа машины Тьюринга считается частью самой машины, но это вопрос терминологии).
Главное отличие машин Тьюринга от реальных ЭВМ (если отвлечься от
ограниченности объема памяти и времени работы последних) - крайняя простота
элементарных шагов; эта простота позволяет легко строить
"трансляторы" с языков реальных машин на язык машины Тьюринга. Можно
сказать даже, что машина Тьюринга - это общая абстрактная схема вычислительной
машины с программным управлением (но стоит подчеркнуть, что Тьюринг придумал
свои машины за несколько лет до появления первых ЭВМ).
Подытоживая все изложенное, можно сказать, что
анализ строения реальных вычислительных процедур убеждает нас в возможности
указать для каждой такой процедуры осуществляющую ее машину Тьюринга. Это и
есть главный довод в пользу тезиса Черча; к нему можно добавить еще два косвенных
довода:
1) для уточнения понятия алгоритма предложено
довольно много конструкций, основанных на различных соображениях и весьма разнообразных
по форме; нередко в двух таких конструкциях трудно на первый взгляд усмотреть
что-либо общее. Однако все эти конструкции равносильны между собой в том
смысле, что всякая функция, вычислимая с помощью какой-либо одной из них,
вычислима и с помощью любой другой. (При этом для каждой пары конструкций их
равносильность удается строго доказать.) Никто еще не смог предложить
конструкцию, приводящую к более широкому классу вычислимых функций;
2) до сих пор во всех случаях, когда для какой-либо
конкретной функции, вычислимость которой в интуитивном смысле не вызывает
сомнений, исследовался вопрос, вычислима ли она также и в смысле какого-либо
уточнения понятия алгоритма (а значит, и всех известных уточнений), на этот
вопрос удавалось получить положительный ответ.
Тезисом Черча часто пользуются для сокращения
доказательств теорем теории алгоритмов: если по ходу рассуждения нужно установить,
что некоторая функция вычислима по Тьюрингу, довольствуются указанием
"неформальной" вычислительной процедуры и построение машины Тьюринга
опускают.
Проблема остановки
- проблема, возникающая после запуска машины Тьюринга, когда могут возникнуть
две ситуации: машина может остановиться через конечное число шагов или будет
работать бесконечно.О проблеме остановки известно, что она неразрешима.
Модуль III. Рекурсии.
Тема 5. Рекурсивные и рекурсивно перечислимые ии
5.1 Понятие рекурсии. Рекурсивные функции.
В основе понятия вычислимой функции лежит широко
распространенный способ вычисления функций натурального аргумента, состоящий в
том, что задается f(0)
и так называемая рекуррентная (от лат. recurro - возвращаюсь) формула
f(n + 1) = h (f(n)) , позволяющая вычислить f(n+1), если известно f(n) , и с помощью этой формулы
последовательно вычисляются f(1),
f(2)
и т. д. Такой процесс последовательного вычисления значений функции называется
рекурсией.
Метод рекурсии дает возможность сводить вычисление
одной функции к вычислению другой: если мы умеем вычислять h, то мы сумеем вычислить и любое
значение f.
Примером
1
может служить функция 2n, которую можно задать
равенствами 20 = 1, 2n+1
= 2*2n,
сводящими вычисление ее значений к вычислению значений функции h(m) = 2(m). Таким образом, если из
вычислимой (в интуитивном смысле) функции получена с помощью рекурсии другая
функция, то эта новая функция также вычислима (в том же смысле).
Разумеется, рекурсия - не единственный способ
получать одни функции из других, при котором вычислимая функция переходит в
разряд вычислимых. Тем же свойством обладает, например, подстановка (суперпозиция):
если мы умеем вычислять функции f(x) и g(x), то мы сумеем вычислить и функцию
g
(f(x)).
Если у нас есть некоторый запас простейших функций,
для которых имеется вычисление, то все функции, которые можно из них получить,
производя сколько угодно раз суперпозиции и рекурсии, с точки зрения любой
разумной интуиции также будут вычислимыми.
Возникает вопрос: насколько широк класс вычислимых
функций, которые можно так получить? Прежде чем выяснять этот вопрос, нужно,
разумеется, уточнить, из какого запаса простейших функций мы исходим. Но
целесообразно также обобщить понятие рекурсии - и даже в двух направлениях.
Во-первых, f(n +1) может зависеть не только от f(n), но и от самого n; в этом случае рекуррентная
формула имеет вид f(n +1) = h (n,f(n)), где h - некоторая заведомо вычислимая
функция двух переменных.
В рассмотренном выше частном случае, когда h - одноместная функция и f(n +1) = h (n,f(n)), функцию f часто называют итерацией (от лат. iteratio - повторение) функции h).
Во-вторых, с помощью рекурсии можно вычислять также
и функции нескольких переменных. При этом все переменные, кроме одной, служат
параметрами, и для каждого фиксированного набора их значений вычисление функции
от оставшейся переменной производится точно так же, как это делалось для
одноместных функций. Это значит, что если мы вычисляем функцию f(x1,…,
xk),
к >1, и рекурсия проводится по переменной xk ,
то f(x1,…,
xk-1,0)
вычисляется по формуле f(x1,…,
xk-1,0)=g(x1,…,
xk-1,0),
a
f(x1,…,xk-1,xk+l) — по формуле f(x1,…,xk-1,xk+l)= h(x1,…,xk-1,xk, f(x1,…,xk-1,xk)), где g и h - заведомо вычислимые функции
вместимости к-1 и к+1, соответственно.
Пример
2.
Пусть f(x1,x2)
= x1*x2,
тогда функция g(x) тождественно равна нулю, h(x1,x2,x3)
равна x3+
x1,
что дает формулы x1*0=0,
x1*(x2+1)
= x1*x2+x1.
Рекурсивные функции используются в вычислительной
математике для изучения эффективно вычислимых функций.
5.2 Рекурсивные и рекурсивно перечислимые множества и предикаты
Задачи о нахождении алгоритмов для вычисления
функций (в частности, предикатов) называют обычно алгоритмическими проблемами;
если алгоритма для вычисления той или иной функции не существует, говорят, что
соответствующая алгоритмическая проблема неразрешима.
Утверждения о неразрешимости проблем распознавания
свойств имеют следующий вид: "Не существует алгоритма, позволяющего по
любому конструктивному объекту из заданного класса А узнать, обладает ли этот
объект данным свойством". Тезис Черча позволяет уточнить эту формулировку
так: "Не существует машины Тьюринга, распознающей данное свойство
объектов класса А". При этом предполагается, что класс А состоит из слов в
некотором конечном алфавите; но в действительности очень часто речь идет о
классах иной природы, элементы которых кодируются словами. Что касается
выражения "машина Тьюринга распознает свойство", то оно понимается
так: машина перерабатывает каждый элемент класса А в "и", если он
обладает данным свойством, и в "л" - если не обладает (вместо
"и" и "л" можно использовать любые другие символы.).
Аналогичным образом уточняются утверждения о не распознаваемости отношений.
Проще всего доказывается неразрешимость некоторых
алгоритмических проблем, относящихся к самой теории алгоритмов, а именно,
проблем распознавания определенных свойств машин Тьюринга. Из них самая простая
- проблема
распознавания самоприменимости. Машина Тьюринга называется
самоприменимой, если она применима к своему собственному коду. В противном
случае машина называется несамоприменимой.
Теорема
1.
Не существует алгоритма, позволяющего для любой машины Тьюринга узнать,
является ли она самоприменимой.
В соответствии со сказанным выше точный смысл этого
утверждения таков: не существует машины Тьюринга, перерабатывающей код любой
самоприменимой машины Тьюринга в "и" и код любой несамоприменимой - в
"л".
Точное понятие алгоритма позволяет выделить среди
всевозможных функций вычислимые, т.е. такие, значения которых можно "в
самом деле находить". Под таким же углом зрения можно рассмотреть и
понятие множества: весьма естественно попытаться среди всевозможных способов
задания множеств выделить "эффективные", т.е. такие, которые
позволяли бы "в самом деле работать" с множествами - указывать их конкретные
элементы и производить над ними вычислительные операции, отвечать для
конкретных объектов на вопрос, входят ли эти объекты в данное множество, и
т.п. При этом, разумеется, придется ограничиться множествами, состоящими из
конструктивных объектов; как и прежде, моделью конструктивного объекта будет
служить слово в конечном алфавите. Однако во многих случаях удобно вместо слов
рассматривать натуральные числа, пользуясь тем, что между словами в заданном
конечном алфавите и натуральными числами можно установить очень простое взаимно
однозначное соответствие.
Говоря о множествах, будем подразумевать множества
натуральных чисел (и говоря о дополнении множества -дополнение до натурального
ряда). Кроме того, будем считать, что фиксирован некоторый конечный алфавит V={ah... ,ар}, Р>1, и во всех
вычислениях на машинах Тьюринга числа представляются словами в этом алфавите
описанным только что способом.
Существуют, как известно, два основных способа
задания множества - путем указания характеристического свойства его элементов и
путем их перечисления. Владея точным понятием алгоритма, мы можем указать для
каждого из этих двух способов "алгоритмический вариант". Для первого
способа такой вариант получается наложением условия, чтобы характеристическое
свойство было распознаваемым (или, как часто говорят, разрешимым), т.е. чтобы
существовал алгоритм, позволяющий по любому слову узнать, обладает ли оно этим
свойством. В алгоритмическом варианте второго способа перечисление должно быть
"в самом деле перечислением", т.е. происходить с помощью некоторого
перечисляющего алгоритма.
В первом варианте не вполне четкое понятие
"характеристическое свойство" можно заменить понятием
"характеристический предикат". Во втором варианте перечисляющий
алгоритм можно понимать как машину Тьюринга, которая "выдает" в
заключительных ситуациях все возможные элементы множества, если
"подавать" на ее ленту в начальных ситуациях все возможные
натуральные числа. Иначе говоря, перечисляемое множество должно быть множеством
значений (одноместной) функции, которую вычисляет некоторая машина Тьюринга с
входным и выходным алфавитами, совпадающими с нашим алфавитом V.
Словарный
предикат - выражение P(x1,…,xk) где xi - слова в некотором
алфавите. Например, x1
пробегает
слова в алфавите D1,
x2
-
слова в алфавите D1
и т.д. Про такой предикат говорят, что он относится к типу D1×D2×…×Dk, указывая область
пробегания каждого аргументного места.
Рекурсивный
предикат - предикат Р типа
D1×D2×…×Dkдля которого вычислима
по Тьюрингу соответствующая характеристическая функция XP.
Предикат
принадлежности множества X - предикат, для которого
выполняется следующее: Р(х) истинно тогда и только тогда, когда х є X, при этом задано множество слов Х
из Е и всякое слово х є Е.
Рекурсивное
множество - это множество Х из Е, для которого рекурсивен
соответствующий предикат принадлежности х є X и где х пробегает множество Е.
Рекурсивными множествами являются многие обычные
множества натуральных чисел: множество четных чисел, множество простых чисел и
т. д.
Множество
называется рекурсивно перечислимым, если оно является
множеством значений некоторой вычислимой функции.
Рекурсивно
перечислимый предикат - предикат Р рекурсивно перечислим,
если существует процедура, позволяющая устанавливать истинность P(x1,...
xk);
если же P(x1,...
xk)
ложно, то эта процедура иногда будет это устанавливать, а иногда будет
продолжаться неограниченно долго.
Теорема.
2.
Применение логических связок к рекурсивным предикатам дает рекурсивные же
предикаты.
Интуитивно предикат Р рекурсивен, если существует
алгоритм, позволяющий выяснить для каждого набора { x1,...
xk}
слов истинно P(x1,...
xk)
или нет.
Обычно арифметические предикаты х ≤у, х + у = z, "х - простое число",
"х делит у" являются рекурсивными.
Здесь и далее под вычислимыми функциями будут подразумеваться
одноместные вычислимые функции.
Теорема
3.
Объединение (U) и пересечение (∩)
рекурсивных множеств рекурсивны; дополнение к рекурсивному множеству
рекурсивно.
Теорема
4.
Объединение и перечисление перечислимых множеств перечислимы.
Теорема
5. Множество
тогда и только тогда перечислимо, когда оно является областью определения
некоторой вычислимой функции.
Теорема
6.
Множество А является рекурсивно перечислимым тогда и только тогда, когда
существует разрешимый предикат R(х,y) такой, что х є A.
Теорема
7. Всякое
разрешимое множество рекурсивно перечислимо.
Теорема8
(теорема Поста). Множество тогда и только тогда разрешимо, когда оно само и
его дополнение рекурсивно перечислимы.
Теорема
9.
Множество номеров самоприменимых машин Тьюринга рекурсивно перечислимо, но не
разрешимо.
Теорема
10.
Существуют непересекающиеся рекурсивно перечислимые множества Е1 и Е2
такие, что никакое разрешимое множество не может содержать Е1,не
имея при этом общих точек с Е2. (Как иногда говорят, Е1 и
Е2 не отделимы разрешимыми множествами.)
Теорема 11. Всякое непустое рекурсивно перечислимое
множество является множеством значений некоторой всюду определенной вычислимой
функции.
Тема 6. Сложность алгоритмов и конечных объектов
6.1 Меры сложности вычислений алгоритмов
В общей теории алгоритмов изучается лишь
принципиальная возможность алгоритмического решения задачи. При рассмотрении
конкретных задач не обращается внимание на ресурсы времени и памяти для
соответствующих им разрешающих алгоритмов. Однако ясно, что принципиальная
возможность алгоритмического решения еще не означает, что оно может быть
практически получено. Поэтому возникает потребность уточнить понятие
алгоритмической разрешимости, введя характеристики слабости алгоритмов,
позволяющие судить об их практической реализуемости. Различные модели
алгоритмов приводят к одному и тому же классу алгоритмически вычислимых
функций. В то же время ясно, что выбор алгоритмической модели, реализующей
алгоритмы, существенно влияет на сложность вычислений. Трудоемкость вычислений,
вообще говоря, не сохраняется при изменении модели алгоритма. Однако имеется
ряд фактов, которые не зависят от вычислительной модели и относятся к так
называемой машинно-независимой теории сложности.
Сложностью
называется "трудность" решения вычислительных проблем, измеренная в
терминах некоторого ресурса, потребляемого в процессе вычислений.
Анализ сложности вычислительных проблем в настоящее
время является областью интенсивных исследований, в которых получаются важные
практические результаты.
Вычислительные ресурсы (в теории алгоритмов) - это
временные или пространственные характеристики процесса вычисления.
Вычислительный ресурс, потребляемый в процессе
вычислений, может быть абстрактным или конкретным.
Критерий сложности - это средство измерения объема
ресурсов, используемых в процессе вычисления.
Классы
сложности - способ группировки алгоритмов или вычислимых
функций в соответствии с их сложностью, при этом функции одного и того же
класса имеют равную вычислительную сложность.
Классификации по сложности обычно подвергаются
формальные языки, распознаваемые машиной Тьюринга.
Введем необходимые определения, выбрав машину
Тьюринга в качестве модели вычислительного устройства. Пусть машина Тьюринга М
вычисляет словарную функцию f(x).
Временной
сложностью называется функция tM(x), равная числу шагов машины М,
выполненному при вычислении f(x), если f(x) определена. Если f(x) не определена, то значение tM(x) считается неопределенным.
Активной
зоной при работе машины М на слове х называется множество
всех ячеек ленты, которые содержат непустые символы либо посещались в процессе
вычисления f(x) головкой машины М.
Пространственной
сложностью (емкостной сложностью) называется функция SM(x), равная длине активной зоны при
работе машины М на слове х, если f(x) определена. Если f(x) не определена, то значение SM(x)считается неопределенным.
Введенные функции сложности TM(x)и SM(x)являются словарными. Удобно
ввести для рассмотрения сложности алгоритма функции натурального аргумента,
которые также называются функциями временной и пространственной сложности.
Временной ресурс (в теории алгоритмов) - функция
вида Time(M ,х), определяемая как число шагов
в вычислении машиной Тьюринга М на входной цепочке символов х до останова М.
Пространственный
ресурс (в теории алгоритмов) - это функция вида Space(M, х) (Space- место, пространство),
определяемая как число квадратов или полей абстрактной ленты в вычислении
машиной Тьюринга М на входной цепочке символов х.
Чтобы не путать пространственный ресурс, необходимый
для работы машины Тьюринга, с пространственным ресурсом, выделяемым для
входной цепочки х, предполагается, что машина Тьюринга имеет ленту ввода,
которая работает только на считывание.
Пространственная
сложность вычисления М– целочисленная функция SM(n), где SM(n) = max (SM(х): |х| = n), где |х| - число элементов или
мощность множества х.
Временная
сложность вычисления М - это целочисленная функция TM(n), где Тм(n) = max(TM(x): |х| = n).
Поведение этих функций в пределе при увеличении
размера задачи n
называется асимптотической временной (соответственно пространственной)
сложностью. Для конкретных задач, как правило, находятся асимптотические
функции сложности.
SM(x) справедливы свойства:
6.2 Сложность конечных объектов
Выяснение
того, какие объекты и действия над ними следует считать точно определенными,
какими свойствами и возможностями обладают комбинации действий, что можно и
чего нельзя сделать с их помощью - все
это стало предметом теории алгоритмов и формальных систем. Главным приложением
теории алгоритмов внутри самой математики явились доказательства невозможности
алгоритмического (т.е. точного и однозначного) решения некоторых математических
проблем.
В
теории алгоритмов фиксируют конкретные конечные наборы исходных объектов
(называемые элементарными) и конечный набор средств построения объектов из
элементарных. Набор элементарных объектов образует конечный алфавит исходных
символов (цифр, букв, и т.д.) из которых строятся другие объекты; типичным
средством построения являются индуктивные определения, указывающие, как строить новые объекты из уже
построенных.
Слова
конечной длины (например, числа) – наиболее
обычный тип алгоритмических данных, а число символов в слове –
естественная единица измерения объема обрабатываемой информации.
Более сложный случай
алгоритмических объектов – формулы. Они
также определяются индуктивно и также являются словами в конечном
алфавите, однако не каждое слово в этом
алфавите является формулой. В этом
случае перед основным алгоритмом идут вспомогательные, которые проверяют, удовлетворяют ли исходные данные нужным требованиям.
Такая проверка называется синтаксическим анализом.
Определение
1. Алгоритм — это конечный набор четких, недвусмысленных
инструкций, следуя которым можно по входным данным определенного вида получать
на выходе некоторый результат.
Определение
2. Конструктивным объектом называется такой объект, который
может быть полностью описан при помощи конечной последовательности символов.
Приведем ряд примеров.
1. Натуральные числа являются конструктивными
объектами. В качестве описания натурального числа можно рассматривать, например,
его десятичную запись. Десятичная запись числа полностью определяет само число;
имея десятичную запись, мы обладаем всей информацией о числе, с которым она
соотносится.
2. Упорядоченные пары натуральных чисел являются
конструктивными объектами. Чтобы полностью описать пару, достаточно перечислить
через запятую описания последовательно первой и второй компонентов этой пары.
3. Конечные последовательности натуральных чисел и
конечные подмножества натурального ряда являются конструктивными объектами.
Описаниями в данном случае служат перечисления через запятую элементов
соответствующих последовательностей в том порядке, в котором они следуют в них
(либо перечисления через запятую элементов соответствующих множеств).
4. Рациональные числа являются конструктивными
объектами. Чтобы полностью описать рациональное число, необходимо всего лишь
задать его числитель и знаменатель.
5. Иррациональные действительные числа не являются
конструктивными объектами. Чтобы задать такое число, необходимо перечислить
бесконечное число знаков после запятой, а это нельзя сделать при помощи
конечной последовательности символов.
6. Бесконечные подмножества натурального ряда не
являются конструктивными объектами. Чтобы полностью задать бесконечное
подмножество, надо перечислить все его элементы.
7. Функции из N в N не являются конструктивными
объектами. Чтобы определить функцию, надо задать ее значения на всех аргументах.
8. Алгоритмы являются конструктивными объектами.
Алгоритм — это конечный набор инструкций. Сам список этих инструкций будет
являться описанием соответствующего алгоритма.
Определение 3 Конструктивным пространством
называется множество всех конструктивных объектов одинакового вида.
Примеры конструктивных пространств — множества N и Q, множество N2, множество конечных
последовательностей натуральных чисел и множество конечных подмножеств
натурального ряда. Множество же N UN2 не является конструктивным пространством: хотя оно
и состоит только из конструктивных объектов, в нем встречаются объекты двух
разных видов. Также не будет конструктивным пространством и произвольное
подмножество N,
например, множество простых чисел: хотя оно и состоит только из конструктивных
объектов одного вида, однако содержит не все такие объекты.
Определение 4 Вычислимой функцией называется функция
из одного конструктивного пространства в другое конструктивное пространство,
для которой существует алгоритм, позволяющий по описанию любого аргумента
получить описание значения функции на этом аргументе.
Предмет теории алгоритмов можно теперь
сформулировать следующим образом: "Исследование функций из одного
конструктивного пространства в другое конструктивное пространство в связи с вопросами
их вычислимости". В связи с этим, поскольку мы ограничиваемся только
"цифровыми" алгоритмами (то есть такими алгоритмами, которые работают
с конструктивными объектами), было бы более уместно назвать наш курс не
"теория алгоритмов", а "теория вычислимости". Однако название
"теория алгоритмов" уже является исторически сложившимся, и менять
его не стоит.
Все вопросы, касающиеся алгоритмов преобразования
объектов одного конструктивного пространства в объекты другого конструктивного
пространства, можно разбить на четыре категории.
1. Вопросы, относящиеся собственно к теории
вычислимости. Это вопросы о том, какие функции являются вычислимыми, а какие
нет, и вопросы типа: "Какие функции станут вычислимыми, если мы объявим
вычислимой какую-нибудь конкретную функцию?"
2. Вопросы, относящиеся к теории сложности. Это
вопросы о том, как быстро (за какое количество шагов) можно вычислить ту или
иную вычислимую функцию, то есть вопросы о сложности оптимальных алгоритмов.
3. Вопросы, относящиеся к программированию или,
более широко, к computer
science.
Это вопросы относятся к конкретным алгоритмам вычислений и к их реализации.
4. Вопросы, относящиеся к такой математической
дисциплине, как методы вычислений. Это вопросы о нахождении приближенных решений
различных дифференциальных и интегральных уравнений при помощи цифровых
алгоритмов.
Модуль IV. Формальные языки класса P и NP.
Тема 7. Теория полиномиальной вычислимости
7.1 Формальные языки класса P.
В теории алгоритмов классом Р (от англ. polynominal) называют множество
задач, для которых существуют «быстрые» алгоритмы решения (время которых
полиноминально зависит от размера входных данных). Класс Р включен в более
широкие классы сложности алгоритма.
В теории сложности рассматриваются только задачи
разрешимости. У задачи разрешимости может быть всего два возможных ответа:
"да" или "нет".
Приведем пример такой задачи. Пусть дано n городов 1, 2,... ,n и известны расстояния между всеми
парами городов. Выезжая из города 1, коммивояжер должен побывать во всех остальных городах по
одному разу и вернуться в исходный город. Определить, существует ли такой
порядок обхода городов, при котором пройденное расстояние не больше чем L,
т.е. необходимо дать ответ на вопрос о существовании маршрута с не более чем
заданной длиной. Решив задачу в оптимизационной постановке, можно дать ответ
на вопрос задачи разрешимости. Для этого достаточно сравнить длину кратчайшего
маршрута с L.
В общем случае, для решения задачи стремятся
построить именно полиномиальный алгоритм. Если же установлена NP-полнота задачи (например, методом
сведения к другой NP-полной
задаче), то построить полиномиальный алгоритм вряд ли удастся и нужно искать
другие методы решения, например использование эвристик.
Полиномиальное
время - характеристика сложности алгоритма, которая
определяется как число элементарных операций, необходимых для реализации
конкретного алгоритма обработки данных с длиной последовательности n,
растущее с увеличением значений n
менее быстро, чем полином р(n).
Задача P
разрешима за полиномиальное время, если существует машина Тьюринга М, решающая ее за полиномиальное время.
Формальные
языки класса Р - класс формальных языков, которые
считаются распознаваемыми за полиномиальное время, точнее, язык L
входит в Р, если существует программа
для машины Тьюринга М и некоторый
полином р(n)
, при котором эта программа, распознает язык L
и для всех неотрицательных значений целых n
соблюдается условие Тм (n) < р(n) , где Тм (n) является
временной сложностью программы.
Определение
1. Класс Р состоит из задач, для которых существуют полиномиальные
алгоритмы решения, т.е. класс Р состоит из задач, которые можно быстро решить.
Определение
2. Класс NP составляют задачи, для которых
существуют полиномиальные алгоритмы проверки правильности предъявляемого
решения, т.е. класс NP состоит
из задач, решение которых можно быстро проверить.
Пример задачи класса Р.
Требуется определить, есть ли в числовом массиве A[1..n] элемент со значением не меньшим,
чем k.
Очевидный алгоритм решения перебирает все элементы массива за время O(n).
Примером задачи класса NP служит задача коммивояжера (туриста) в постановке задачи разрешимости
прохождения некоторого маршрута. Действительно, если нам дан некоторый маршрут
длиной не более чем k,
то за время O(n) можно проверить, что он
действительно имеет такую длину, и тем самым убедиться в его существовании. Для
этого нужно перебрать все n
содержащихся в нем переходов между городами и просуммировать их длины.
Очевидно включение P, которое является NP (для проверки решения задачи
класса P достаточно решить ее полиномиальным
алгоритмом). Вопрос, является ли это включение строгим, остается одним из
центральных вопросов теории сложности. Большинство специалистов полагают, что Р
≠ NP.
Одним из аргументов в пользу последнего служит существование NP-полных задач.
Определение
3. Задача называется NP-полной,
если она принадлежит классу NP
и к ней за полиномиальное время можно свести любую другую задачу этого класса.
Если какая-нибудь (любая) NP-полная задача имеет полиномиальный
алгоритм решения, то все NP-полные
задачи полиномиально разрешимы и, как следствие, P=NP (в этом случае за полиномиальное
время разрешимы все задачи класса NP).
Можно сказать и иначе. Если P=NP, то NP-полные задачи разрешимы за
полиномиальное время.
NP-полные
задачи являются наиболее трудными в классе NP. Ни для одной из них никому не
удалось построить полиномиальный алгоритм решения. Это укрепляет нас во мнении,
что P
≠ NP.
Как правило, полиномиальные алгоритмы работают
относительно быстро, а алгоритмы со сложностью, превышающей полиномиальную, —
медленно.
Эти утверждения не следует воспринимать как догму.
Трудно назвать быстрым алгоритм со временем работы:
T
(n)
= 10100n или T (n) = n100.
Иногда вместо полиномиальных применяют
неполиномиальные алгоритмы решения. Например, задачи линейного программирования
относятся к классу полиномиальных задач, однако на практике эффективнее других
зарекомендовал себя симплексный метод решения, имеющий в худшем случае
экспоненциальную сложность.
Класс языков с экспоненциально ограничивающими
функциями представляет собой объединение бесконечного множества языков с
полиномиальными ограничивающими функциями.
Алгоритм, сложность которого вырастает по
экспоненте, называется экспоненциально ограниченным, при этом подразумевается,
что алгоритм завершается.
7.2 Замечания к задачам класса P
Замечания к задачам класса P:
1. В определении класса Р
существенным является фиксация схемы кодирования α. Многие естественные схемы кодирования полиномиально
эквивалентны, т.е. позволяют переходить от одного кода задачи к другому коду за
полиномиальное время от длины кода. В этом случае принадлежность задачи П
классу Р определяется инвариантно по
отношению к схемам кодирования. Однако это справедливо не всегда и, вообще
говоря, класс сложности Р зависит от
схемы кодирования, поэтому там, где схема кодирования не очевидна или может
повлиять на класс сложности, ее следует указывать явно.
2. Класс Р определен через функцию временной
сложности машины Тьюринга. Можно сделать соответствующие определения через
любую другую алгоритмическую модель. Однако имеется ряд фактов о полиномиальной
эквивалентности временных функций сложности многих типов вычислительных
моделей, что позволяет утверждать, что класс Р определен однозначно для "разумных" вычислительных
моделей.
Необходимо отметить, что имеется существенное
различие между алгоритмами полиномиальной и экспоненциальной сложности. Любой
полиномиальный алгоритм более эффективен при достаточно больших размерах входа.
Кроме того, полиномиальные алгоритмы лучше реагируют на рост производительности
ЭВМ.
Полиномиальные алгоритмы обладают свойством
замкнутости: их можно комбинировать, используя один в качестве
"подпрограммы" другого и при этом результирующий алгоритм будет
полиномиальным. В силу приведенных причин используется следующая терминология:
полиномиальные алгоритмы называют эффективными, полиномиально решаемые задачи
называют легкорешаемыми, а экспоненциально решаемые задачи - труднорешаемыми.
Для практики важным является классификация задач по признаку труднорешаемости,
хотя установление легкорешаемости задачи еще не означает ее практическую
решаемость.
Тема 8.Недетерминированная машина Тьюринга и языки класса NP
8.1 Недетерминированная машина Тьюринга и языки класса NP
Введем понятие недетерминированной машины Тьюринга.
Недетерминированная
машина Тьюринга - это машина Тьюринга М, в которой на
каждом этапе вычислений существуют альтернативы.
Ее отличие от обычной машины Тьюринга заключается в
том, что недетерминированная машина (НМ) имеет дополнительно угадывающий
модуль (УМ), который может только записывать на ленту слова из внешнего
алфавита (см. рис. 1). Поскольку речь
идет о задачах распознавания, то удобно считать, что машина имеет два
заключительных состояния qY и qN , соответствующие
ответам "ДА" и "НЕТ". Работа машины имеет две стадии. 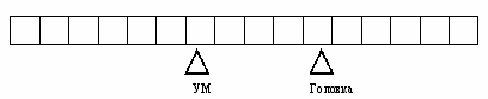
Рис.1
Вид состояния недетерминированной машины Тьюринга
Стадия
1 - угадывание. В начальный момент на ленте записано
слово х = х1,..., хn - код индивидуальной
задачи I, начиная с ячейки 1. В ячейке 0 записан знак раздела *. Угадывающий
модуль просматривает ячейку 1. Затем УМ пишет произвольное слово с(х) по одной
букве за такт в каждой ячейке с номерами 1, 2, 3,.... В итоге стадии 1 конфигурацией
машины будет с(х) * q1x.
Стадия
2 - решение. На этой стадии недетерминированная машина работает
как обычная машина
Тьюринга в конфигурации с(х) * q1x . Если машина через конечное число
шагов приходит в состояние qY
то говорят, что она принимает конфигурацию с(х) * q1x . Будем говорить, что
недетерминированная машина принимает х, если существует слово с(х) такое, что
принимается конфигурация с(х) * q1x.
Классы
сложности могут быть определены и для программ недетерминированной
машины Тьюринга.
Определим время работы недетерминированной машины,
положив
tHM
(х) = t1
(х) +t2
(х) (если х принимается),
где t1(x)- время работы на стадии 1,
т.е., по определению, t1(x)= (c(х));
t2(x) - время работы на стадии 2, т.е.,
по определению, t2(x)= (c(х)*x);
М - соответствующая (обычная) машина Тьюринга.
Определим ТHM (n) = max(tHM(х) : |х| = n).
Недетерминированная машина НТ решает задачу Z за полиномиальное время, если tHM(n) = 0(p(n)) для некоторого полинома р.
Заметим, что временная функция определена только для
тех индивидуальных задач х, которые
принимаются машиной НТ.
Класс
NP
языков - класс формальных языков, которые считаются
распознаваемыми за полиномиальное время недетерминированной машиной Тьюринга.
Рассмотрим теперь вопрос о взаимоотношении между
введенными классами Р и NP.
Ясно, что Р принадлежит NP
. Имеется много причин считать это включение строгим, однако этот факт пока не
доказан.
Теорема
1.
Если задача Z принадлежит NP , то существует такой полином Р ,
что задача Z
может быть решена детерминированным алгоритмом со сложностью 0(2р(n))
, - размер Z.
Доказательство.
Пусть
НТ - недетерминированная машина Тьюринга, решающая задачу Z , q(n) - полином, ограничивающий
временную функцию сложности НТ. Не нарушая общности, можно считать, что q(n) = c1
nc2 , (c1,
c2 - константы). По определению класса NP, если вход х длины n принимается НТ, то существует
слово с(х) длины не более чем q(n) такое, что НТ дает ответ
"ДА" не более чем за q(n)
шагов. Значит, общее число возможных слов-догадок не более чем kq(n),
где к - мощность внешнего алфавита
НТ. Можно считать, что все догадки имеют длину в противном случае их можно
подравнять. Теперь можно представить детерминированный алгоритм решения задачи Z, который на каждом из kq(n)
слов-догадок реализует стадию 2 работы НТ и работает q(n)
тактов. Алгоритм дает ответ "ДА", если найдется слово-догадка,
приводящее к принимающему вычислению. Время работы данного алгоритма q(n)*kq(n)
. Ясно, что существует подходящий полином р(n) и сложность описанного алгоритма
не превосходит O(2p(n)).
8.2 Замечания к задачам класса NP
К задачам класса NP имеются следующие замечания:
1. Класс NP - один и тот же для различных вычислительных моделей,
использующих недетерминированные операции.
2. Класс Р замкнут относительно дополнения задач.
Для класса NP
этого утверждать нельзя. Дополнением
Ᾱ задачи распознавания А
называют задачу, в которой коды задач с ответом "ДА" в точности
соответствуют кодам задач А, которые не имеют ответ "ДА". Класс
задач, являющихся дополнениями к задачам класса NP, обозначают CO-NP.
Понятие
NP-полной
задачи.
Если
Р≠ NP,
то задачи из NP
\ Р являются трудноразрешимыми. Цель дальнейших рассуждений состоит в
доказательстве того, что существуют конкретные задачи Z , для которых справедливо
включение задачи Z
Є NP
\ Р , если Р ≠ NP
. Соответствующие результаты основаны на понятии полиномиальной сводимости
задач. Пусть Z1,
Z2 - две задачи распознавания, задаваемые в
алфавитах А1 и А2
соответственно. Будем говорить, что задача
Z1
полиномиально сводится к задаче Z2
(обозначение Z1∞
Z2),
если существует словарная функция
f : А1 → А2
такая, что выполнены условия:
1) f - полиномиально вычислима;
2) x
Є А1 выполнено, х - индивидуальная
↔ О f
(х) Є А2 - индивидуальная
задача Z1
с ответом "ДА" и задача Z2 с ответом
"ДА".
Теорема
2.
Если выполнено Z1∞
Z2
и
Z2
Є Р , то Z1
Є Р.
Доказательство.
Предположим полиномиальный алгоритм решения задачи Z1
: х Є Z1,
найдем f
(х) Є Z2
и применим к f(x) полиномиальный алгоритм. Если
получен ответ "ДА", то х имеет ответ "ДА". В противном
случае х имеет ответ "НЕТ". Время работы алгоритма не превосходит
pf
(|х|) + pf
(p2|х|
)), где
pf
- полином, ограничивающий время вычисления функции /, участвующей в сведении Z1∞
Z2; p2 - полином,
ограничивающий время решения задачи Z2. Теорема доказана.
Перечень основной и дополнительной учебной литературы, необходимой для освоения дисциплины.
Основная литература
1.
Игошин В.И. Теория алгоритмов.
Учеб.пособие. – М.: ИНФРА –М , 2014. -318 с. – (Высшее образование).
2.
Игошин В.И. Задачи и упражнения по
математической логики и теории алгоритмов. Издательский центр «Академия», 2005.
- 304 с.
3.
Лихтарников Л.М., Сукачева, Т.Г.
Математическая логика. Издательство «Лань», 2008. - 288 с.
Дополнительная
литература
4.
Романович В.А. Лекции по математической
логике. Издательство ТГУ, 2005 - 408 с.
5.
Шень А. Программирование: теоремы и
задачи..- 5-е изд., стереотип. – М.: МЦНМО, 2014. -296 с.: ил.
Перечень ресурсов информационно-телекоммуникационной сети «Интернет», необходимых для освоения дисциплины.
1)
http://elibrary.ru/defaultx.asp
- Научная электронная библиотека (НЭБ)
2)
http://elibrary.ru/projects/subscription/rus_titles_open.asp-
БД российских научных журналов на Elibrary.ru (РУНЭБ)
3)
http://www.bibloclub.ru-
Электронно-библиотечная система «Университетская библиотека онлайн»
4)
http://www.citforum.ru‑
Сервер информационных технологий