Лабораторная работа №1
Свойства
статистического распределения. Построение гистограмм.
Теоретическая
часть
Цель работы: приобретение
навыков группирования и обработки первичной статистической информации в
интерактивной среде Excel.
Задание. Проранжировать первичный ряд
данных, определить частоты и частости нового ряда,
найти абсолютную и относительные плотности
распределения, графически изобразить данные в виде эмпирической функции
распределения, гистограмм частот.
Теоретическая часть
Математическая
статистика – наука, изучающая методы исследования закономерностей в массовых
случайных явлениях и процессах по данным, полученным из конечного числа
наблюдений за ними.
Построенные на основании этих методов закономерности
относятся не к отдельным испытаниям, из повторения которых складывается данное
массовое явление, а представляют собой утверждения об общих вероятностных
характеристиках данного процесса. Такими характеристиками могут быть
вероятности, плотности распределения вероятностей, математические ожидания,
дисперсии и т.п.
Найденные характеристики позволяют построить вероятностную модель изучаемого явления.
Применяя к этой модели методы теории вероятностей, исследователь может решать
технико–экономические задачи, например, определять вероятность безотказной
работы агрегата в течение заданного отрезка времени. Таким образом, теория
вероятностей по вероятностной модели процесса предсказывает его поведение, а
математическая статистика по результатам наблюдений за процессом строит его
вероятностную модель. В этом состоит тесная взаимосвязь между данными науками.
Очевидно, что для обнаружения закономерностей
случайного массового явления необходимо провести сбор статистических сведений,
т.е. сведений, характеризующих отдельные единицы каких–либо массовых явлений.
Пусть, например, мы располагаем материалом о числе дефектных изделий в
изготовленной в определенных условиях партии продукции. Проблемы возникают
тогда, когда на основании этой информации мы захотим сделать выводы
относительно качества производства продукции, выпускаемой предприятием. Нас
может интересовать вероятность производства дефектного изделия, средняя
долговечность всех выпускаемых изделий и т.д. Собранный материал
рассматривается лишь как некоторая пробная группа, одна из многих возможных
пробных групп. Конечно, выводы, сделанные на основании этого ограниченного
числа наблюдений, отражают данное массовое явление лишь приближенно.
Математическая статистика указывает, как наилучшим способом использовать
имеющуюся информацию для получения по возможности более точных характеристик
массового явления.
Генеральная
и выборочная совокупности
Для обнаружения закономерностей, описывающих
исследуемое массовое явление, необходимо иметь опытные данные, полученные в
результате обследования соответствующих объектов, отображающих изучаемое
явление. Математическая статистика занимается установлением закономерностей,
которым подчинены массовые случайные явления, на основе обработки
статистических данных, полученных в результате наблюдений.
Определим основные понятия математической статистики.
Генеральная совокупность– все множество имеющихся объектов.
Выборка – набор объектов, случайно отобранных из генеральной
совокупности.
Объем генеральной совокупности N и объем
выборки n – число объектов в рассматриваемой совокупности.
Виды выборки:
Повторная – каждый отобранный объект перед выбором следующего
возвращается в генеральную совокупность;
Бесповторная – отобранный объект в генеральную совокупность не
возвращается.
Замечание. Для того, чтобы по
исследованию выборки можно было сделать выводы о поведении интересующего нас
признака генеральной совокупности, нужно, чтобы выборка правильно представляла
пропорции генеральной совокупности, то есть была репрезентативной (представительной). Учитывая закон больших чисел,
можно утверждать, что это условие выполняется, если каждый объект выбран
случайно, причем для любого объекта вероятность попасть в выборку одинакова.
Пусть интересующая нас случайная величина Х принимает в выборке значение х1
– п1 раз, х2 – п2 раз, …, хк – пк раз, причем ![]() где п – объем выборки.
Тогда наблюдаемые значения случайной величины х1, х2,…, хк называют вариантами,
а п1, п2,…, пк – частотами.
Если разделить каждую частоту на объем выборки, то получим относительные частоты
где п – объем выборки.
Тогда наблюдаемые значения случайной величины х1, х2,…, хк называют вариантами,
а п1, п2,…, пк – частотами.
Если разделить каждую частоту на объем выборки, то получим относительные частоты ![]() Последовательность вариант, записанных в порядке
возрастания, называют вариационным рядом,
а перечень вариант и соответствующих им частот или относительных частот – статистическим рядом:
Последовательность вариант, записанных в порядке
возрастания, называют вариационным рядом,
а перечень вариант и соответствующих им частот или относительных частот – статистическим рядом:
|
xi |
x1 |
x2 |
… |
xk |
|
ni |
n1 |
n2 |
… |
nk |
|
wi |
w1 |
w2 |
… |
wk |
Пример.
При
проведении 20 серий из 10 бросков игральной кости число выпадений шести очков
оказалось равным 1,1,4,0,1,2,1,2,2,0,5,3,3,1,0,2,2,3,4,1.
Составим вариационный ряд:
0,1,2,3,4,5.
Статистический ряд для
абсолютных и относительных частот имеет вид:
|
xi |
0 |
1 |
2 |
3 |
4 |
5 |
|
ni |
3 |
6 |
5 |
3 |
2 |
1 |
|
wi |
0,15 |
0,3 |
0,25 |
0,15 |
0,1 |
0,05 |
Если исследуется некоторый непрерывный признак, то
вариационный ряд может состоять из очень большого количества чисел. В этом
случае удобнее использовать группированную выборку. Для ее
получения интервал, в котором заключены все наблюдаемые значения признака,
разбивают на несколько равных частичных интервалов длиной h, а затем
находят для каждого частичного интервала ni – сумму частот вариант, попавших в i-й интервал.
Составленная
по этим результатам таблица называется группированным
статистическим рядом:
|
Номера интервалов |
1 |
2 |
… |
k |
|
Границы интервалов |
(a, a + h) |
(a +
h, a +2h) |
… |
(b – h, b) |
|
Сумма частот вариант, попав- ших в интервал |
n1 |
n2 |
… |
nk |
Полигон частот. Выборочная функция
распределения и гистограмма.
Для наглядного представления о поведении исследуемой
случайной величины в выборке можно строить различные графики. Один из них – полигон частот: ломаная, отрезки которой соединяют точки с координатами (x1, n1), (x2, n2),…, (xk, nk), где xi
откладываются на оси абсцисс, а
ni– на оси ординат. Если на оси ординат откладывать не
абсолютные (ni), а относительные (wi) частоты, то получим полигон
относительных частот.
По аналогии с функцией распределения случайной
величины можно задать некоторую функцию, относительную частоту события X<x.
Определение. Выборочной
(эмпирической) функцией распределения называют функцию F*(x),
определяющую для каждого значения х
относительную частоту события X<x. Таким образом,
![]() ,
,
где
пх
– число вариант, меньших х, п – объем выборки.
Замечание. В отличие от эмпирической функции распределения,
найденной опытным путем, функцию распределения F(x) генеральной совокупности называют теоретической функцией распределения. F(x)
определяет вероятность события X<x, а F*(x) – его относительную частоту. При достаточно больших п, как следует из
теоремы Бернулли, F*(x) стремится по вероятности к F(x).
Из
определения эмпирической функции распределения видно, что ее свойства совпадают
со свойствами F(x), а именно:
1)
0 ≤ F*(x) ≤
1.
2)
F*(x) – неубывающая функция.
3)
Если х1 –
наименьшая варианта, то F*(x) = 0 при х ≤
х1;
если хк– наибольшая варианта, то
F*(x) = 1 при х > хк .
Для непрерывного признака графической иллюстрацией
служит гистограмма, то есть
ступенчатая фигура, состоящая из прямоугольников, основаниями которых служат
частичные интервалы длиной h, а высотами –
отрезки длиной ni /h
(гистограмма частот) или wi/h (гистограмма
относительных частот). В первом случае площадь гистограммы равна объему
выборки, во втором – единице .
Вычисление
выборочных характеристик в Excel
Вычисление частот. Для вычисления частот ni можно использовать функцию ЧАСТОТА, обращение к которой
имеет вид:
=ЧАСТОТА(массив_данных;массив_границ),
где массив_данных –
адреса ячеек, для которых вычисляется частота ![]() ; массив_границ – адреса ячеек, в которых размещаются упорядоченные
по возрастанию значения
; массив_границ – адреса ячеек, в которых размещаются упорядоченные
по возрастанию значения ![]() , где
, где ![]() – число
интервалов.
– число
интервалов.
При использовании этой функции необходимо помнить:
1.
Функция
ЧАСТОТА вводится как формула массива, т.е. предварительно выделяется интервал ячеек,
в который будут помещены вычисленные частоты (число ячеек должно быть на 1
больше числа границ), затем вводится функция ЧАСТОТА с соответствующими
аргументами, потом одновременно нажимаются клавиши [Ctrl] + [Shift] + [Enter].
2.
Функция
ЧАСТОТА игнорирует пустые ячейки и текстовые данные.
3.
Если
массив_границ
не содержит возрастающих значений границ и интервалов, то осуществляется
автоматическое вычисление границ интервалов равной ширины, причем число
интервалов равно корню квадратному из числа элементов массива_данных.
Результатом работы является массив значений, определяемый по следующему
правилу: первый элемент равен числу n0 элементов массива_данных меньше![]() ; последний элемент равен числу
; последний элемент равен числу ![]() элементов массива_данных
больше
элементов массива_данных
больше ![]() ; остальные элементы определяются как числа nj элементов xi массива_данных, удовлетворяющих условию
; остальные элементы определяются как числа nj элементов xi массива_данных, удовлетворяющих условию
![]() ,
, ![]() .
.
Другими
словами, кроме ![]() значений частот
nj,
значений частот
nj,![]() , соответствующих
, соответствующих ![]() интервалам,
вычисляются частоты n0 (число значений
интервалам,
вычисляются частоты n0 (число значений ![]() , лежащих левее
, лежащих левее ![]() ) и
) и ![]() (число значений
(число значений
![]() , лежащих правее
, лежащих правее ![]() ).
).
![]() ,
, ![]() . ☻
. ☻
Для подсчета количества элементов выборки
(т.е. объема выборки n) используется функция СЧЁТ, обращение к которой
имеет вид:
СЧЁТ(массив_данных),
где массив_данных – адреса ячеек или
числовые константы.
Функция
МАКС вычисляет
максимальное значение из заданных аргументов. Обращение к ней имеет вид:
=МАКС(арг1; арг2; …; арг30),
где арг1; арг2; …; арг30
– числовые константы или адреса ячеек, содержащих числовые величины.
Функция
МИН вычисляет
минимальное значение из заданных аргументов. Обращение к ней имеет вид:
=МИН(арг1; арг2; …; арг30),
где арг1; арг2; …;
арг30 – числовые константы или адреса ячеек, содержащих числовые величины.
Пример решения задачи в Excel
Условие. Имеются разрозненные данные по рентабельности
активов банков с доходами от 50 до 100 млн. долл.:
1,51; 0,85; 1,37;
1,62; 0,80; 2,0; 1,49; 1,58; 1,75; 1,24; 1,28; 1,04; 1,98; 1,15; 1,66; 1,33;
1,73; 1,13; 1,36; 1,28.
По этим данным
получить сгруппированный статистический ряд распределения, найти и построить эмпирическую функцию распределения выборки,
построить гистограммы частот.
Выполнение задания.
1. В программной
среде Excel заполняется
столбец исходных данных (рис. 1).
2. Первоначально, начиная с ячейки А5 (рис.1), введем в столбец А 20 элементов выборки. (диапазон А5:А24).Выполняется
сортировка столбца А - первичного ряда в
порядке возрастания. В результате получен новый интервальный ранжированный ряд.
На рис.1 приведен уже результат сортировки по возрастанию.
Рис. 1.
Результат сортировки по возрастанию.
3.Определяются
частоты нового ряда. Для этого используются данные об объеме совокупности исследуемых банков n. Найдем
объем данной выборки n, используя
встроенную функцию СЧЁТ(массив_данных).
Дискретный
вариационный ряд разбивается на интервалы, число которых подсчитывается по
формуле Стерджесса
k = ![]() 1 + 3,322 lgn
1 + 3,322 lgn![]() ,
(1)
,
(1)
в которой
квадратные скобки означают округление числа 5,32 , тогда k = 5. Длина
частичного интервала (интервальный шаг) определяется по формуле
![]() (2)
(2)
Значения xmax = 2,0 , xmin = 0,8 находим, используя соответствующие встроенные
функции МАКС и МИН. Определяем интервальный шаг h = 0,24. Тогда границы интервалов будут такими:
|
x0= |
xmin =0,8 ; |
|
x1= |
xmin + h = 1,04 ; |
|
x2= |
xmin +2h = 1,28 ; |
|
x3= |
xmin +3h = 1,52 ; |
|
x4= |
xmin +4h = 1,76 ; |
|
x5= |
xmin +5h = 2 |
Затем, начиная с ячейки B11, введем границы заданных интервалов от xmin до xmax, соблюдая интервальный шаг h (см. рис. 2). Введем рядом эти же данные в диапазон
C11:C16, как на рис.2.
После подготовки этих данных, для определения частот ni,
выделяем ячейки D11:D16 (число ячеек должно быть на 1 больше
числа границ!), вводим выражение
=ЧАСТОТА (А5:А24;В11:В16)
и нажимаем
одновременно клавиши [Ctrl] + [Shift]
+ [Enter]. В ячейках D11:D15 появляется результат выполнения функции
(см. рис. 2.). Таблицу
оформить согласно рис.2.
Определив
количество банков, принадлежащих каждому из интервалов (частоты ni), получим
сгруппированный статистический
ряд распределения.
Для вычисления
относительных частот wi (частостей) необходимо частоты поделить на число элементов
выборки, т.е. wi=ni/n. Эти вычисления реализованы в ячейках E11:E15 (см. рис.2) . Здесь обратите внимание на абсолютную адресацию ячейки,
содержащей значение n! Для контроля
правильности вычисления частот ni и частостей wi в ячейках D17, E17
определить контрольные суммы по
соответствующим столбцам.
3. Найдем эмпирическую функцию
распределения
![]() ,
,
где пх – число вариант, меньших х, п
– объем выборки. Результаты представлены на рис.2.
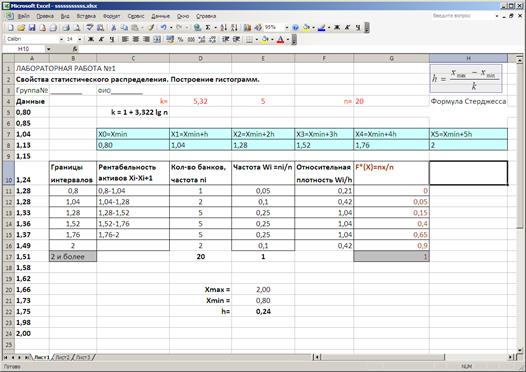
Рис. 2.Примерный вид таблицы
при расчете частостей и эмпирической функции
распределения.
5.
Построим графики эмпирической функции распределения и гистограмм частот. Для
функции F*(x) предварительно выделим
данные по столбцам Границы интервалов и ![]() . Затем, открывая
вкладку меню Вставка,
строим график, выбирая соответствующие опции меню. Названия диаграмм, осей
вводим, открывая контекстное меню
диаграммы.
. Затем, открывая
вкладку меню Вставка,
строим график, выбирая соответствующие опции меню. Названия диаграмм, осей
вводим, открывая контекстное меню
диаграммы.
Для гистограмм частот
выделяем данные по столбцам: Рентабельность активов Xi-Xi+1
и частота ni или wi.
Получаем следующее графическое представление
данных для
эмпирической функции распределения:
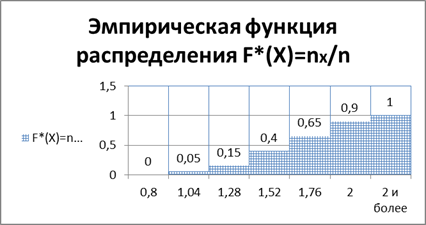
Рис.3.Эмпирическая
функция распределения.
Для гистограмм частот и гистограмм
относительных частот:
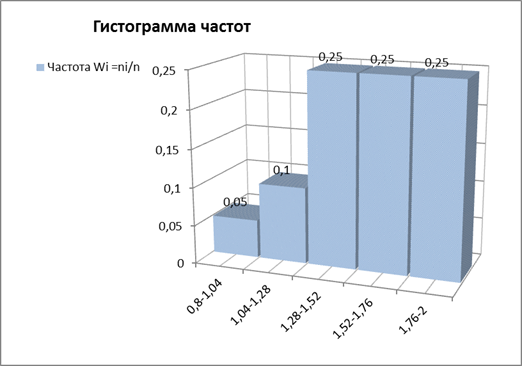
Рис.4 Графическое представление
данных для гистограммы частот
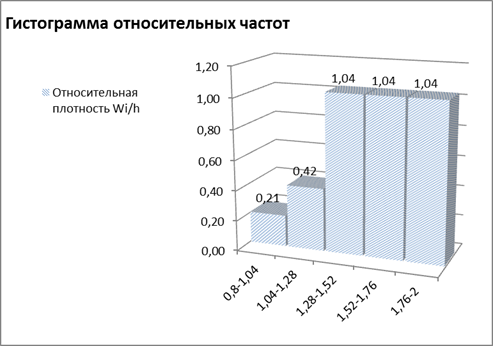
Рис.5.
Графическое представление данных для гистограммы относительных частот
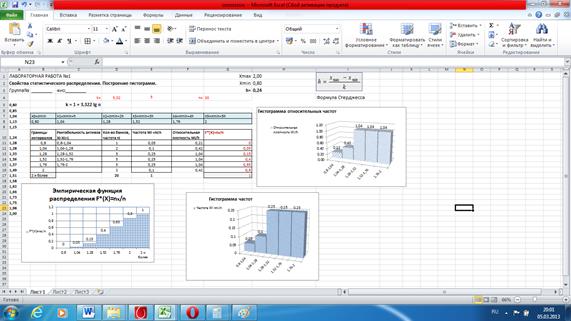
Рис.6. Результат выполнения типового
примера Лабораторной работы №1.
Варианты заданий для
самостоятельного решения.
Варианты
указаны римскими цифрами.
|
Вар. |
I |
II |
III |
IV |
V |
VI |
VII |
VIII |
IX |
X |
XI |
XII |
XIII |
XIV |
XV |
|
1 |
0,52 |
0,65 |
0,89 |
1,21 |
1,25 |
1,69 |
1,45 |
1,85 |
0,35 |
0,68 |
0,48 |
1,25 |
1,79 |
1,96 |
0,86 |
|
2 |
1,89 |
1,63 |
1,06 |
1,69 |
1,85 |
1,52 |
0,42 |
1,64 |
1,05 |
1,78 |
1,51 |
1,22 |
1,11 |
1,54 |
1,88 |
|
3 |
1,22 |
0,53 |
1,29 |
0,62 |
1,84 |
0,94 |
1,21 |
1,68 |
1,43 |
1 |
0,49 |
1,22 |
1,95 |
1,05 |
1,22 |
|
4 |
1,43 |
1,45 |
1,06 |
0,41 |
1,98 |
0,78 |
1,78 |
1,28 |
1,21 |
1,43 |
0,65 |
0,74 |
1,01 |
1,43 |
0,63 |
|
5 |
0,87 |
1,34 |
1,06 |
0,43 |
0,89 |
1,21 |
1,54 |
1,78 |
0,73 |
1,11 |
0,85 |
0,65 |
1,54 |
1,73 |
1,64 |
|
6 |
1,55 |
1,68 |
0,69 |
1,75 |
0,95 |
1,54 |
1,66 |
1,37 |
1,25 |
0,74 |
0,53 |
1,01 |
1,55 |
1,51 |
1,01 |
|
7 |
1,14 |
1,88 |
1,73 |
0,43 |
1,96 |
0,50 |
1,10 |
1,37 |
1,43 |
1,05 |
0,63 |
1,21 |
0,79 |
1,83 |
1,43 |
|
8 |
0,65 |
0,99 |
1,56 |
1,48 |
1,43 |
0,65 |
1,12 |
0,89 |
1,12 |
1,24 |
0,25 |
1,01 |
0,74 |
1,78 |
1,33 |
|
9 |
0,65 |
1,75 |
0,94 |
0,54 |
0,97 |
1,05 |
1,25 |
1,51 |
1,14 |
1,22 |
0,68 |
1,54 |
1,43 |
1,42 |
1,21 |
|
10 |
1,89 |
0,59 |
1,75 |
1,67 |
1,99 |
1,25 |
1,48 |
1,88 |
1,64 |
0,78 |
1,11 |
0,75 |
0,95 |
0,63 |
1,69 |
|
11 |
1,14 |
2,10 |
0,92 |
1,52 |
1,54 |
2,01 |
1,03 |
1,56 |
0,75 |
0,89 |
0,72 |
1,25 |
0,83 |
1,64 |
0,65 |
|
12 |
0,91 |
1,87 |
0,89 |
0,65 |
1,05 |
0,94 |
1,66 |
1,11 |
0,63 |
1,92 |
1,43 |
2,14 |
1,37 |
0,89 |
1,54 |
|
13 |
1,37 |
1,43 |
0,92 |
1,68 |
1,47 |
1,14 |
0,65 |
2 |
1,07 |
1,64 |
0,98 |
1,01 |
0,64 |
1,78 |
0,89 |
|
14 |
1,43 |
1,36 |
1,25 |
1,49 |
1,03 |
1,62 |
1,96 |
1,43 |
1,08 |
0,72 |
0,35 |
0,89 |
0,63 |
1,47 |
1,61 |
|
15 |
1,78 |
1,37 |
1,45 |
1,37 |
1,21 |
1,78 |
1,62 |
1,22 |
0,74 |
1,23 |
1,78 |
0,67 |
1,25 |
1,63 |
1,37 |
|
16 |
0,96 |
0,89 |
1,51 |
0,63 |
1,07 |
0,59 |
1,43 |
1,01 |
1,51 |
1,21 |
0,74 |
0,76 |
1,05 |
1,22 |
1,51 |
|
17 |
1,25 |
1,65 |
1,65 |
1,76 |
1,42 |
1,45 |
1,51 |
1,23 |
1,11 |
1,01 |
1,21 |
1,51 |
0,89 |
1,92 |
2 |
|
18 |
1,11 |
1,21 |
1,78 |
1,25 |
1,65 |
1,29 |
1,81 |
0,91 |
0,65 |
1,37 |
0,86 |
0,32 |
0,99 |
1,88 |
1,65 |
|
19 |
0,58 |
1,43 |
1,08 |
1,56 |
2 |
1,21 |
1,11 |
0,91 |
1,88 |
0,63 |
1,05 |
0,63 |
0,69 |
0,74 |
1,51 |
|
20 |
1,56 |
1,52 |
1,04 |
1,37 |
1,08 |
1,11 |
1,70 |
1,25 |
1,54 |
1,09 |
0,39 |
0,67 |
1,06 |
1,25 |
0,65 |
|
21 |
1,09 |
1,34 |
1,23 |
0,89 |
1,84 |
1,44 |
1,37 |
0,63 |
0,85 |
0,78 |
1,89 |
1,54 |
1,56 |
1,75 |
1,11 |
|
22 |
2 |
1,37 |
1,42 |
1,66 |
1,54 |
1,11 |
1,67 |
0,63 |
0,68 |
1,25 |
0,45 |
1,05 |
1,15 |
1,32 |
1,56 |
|
23 |
1,21 |
1,87 |
1,05 |
0,74 |
1,89 |
1,22 |
1,74 |
1,54 |
1,55 |
0,46 |
1,01 |
0,64 |
2,12 |
1,62 |
0,74 |
|
24 |
0,99 |
1,25 |
1,67 |
1,66 |
1,84 |
1,98 |
1,42 |
1,21 |
0,89 |
1,43 |
1,64 |
1,11 |
1,24 |
1,84 |
1,05 |
|
25 |
1,45 |
1,21 |
0,65 |
1,64 |
1,42 |
1,32 |
1,83 |
0,95 |
1,22 |
1,23 |
0,89 |
0,85 |
1,88 |
0,65 |
1,78 |
|
26 |
0,89 |
1,47 |
1,58 |
1,57 |
1,37 |
0,89 |
1,06 |
0,97 |
1,24 |
0,67 |
1,05 |
0,81 |
1,25 |
1,74 |
1,37 |
|
27 |
2 |
1,14 |
1,02 |
1,58 |
1,65 |
1,64 |
1,43 |
1,25 |
1,21 |
1,54 |
0,81 |
1,43 |
1,13 |
1,71 |
1,64 |
|
28 |
1,87 |
1,35 |
1,67 |
1,78 |
1,24 |
1,56 |
1,59 |
1,05 |
0,71 |
1,51 |
1,22 |
1,85 |
1,22 |
1,21 |
1,25 |
|
29 |
0,62 |
1,11 |
1,79 |
1,52 |
1,06 |
1,42 |
1,04 |
0,74 |
1,78 |
1,65 |
1,54 |
0,93 |
1,51 |
1,01 |
1,35 |
|
30 |
1,23 |
1,02 |
1,21 |
1,85 |
1,06 |
1,56 |
0,89 |
1,28 |
1,05 |
0,65 |
0,41 |
0,89 |
0,69 |
1,65 |
1,74 |
Контрольные вопросы
для самопроверки .
1.Генеральная
и выборочная совокупности.
2.
Статистическое распределение выборки.
3. Встроенные в Excel функции составления статистического ряда
распределения
4. Принцип построения интервального статистического ряда при помощи
формулы Стерджесса.
5.Эмпирическая
функция распределения и вариационный
ряд.
6. Гистограмма. Мода и
медиана.