Лекция
8. Математическая
модель системы связи
Расстоянием Хэмминга,
код Грея,
Свойства Расстояния Хэмминга,
Вес двоичного
слова,
нижняя граница Хэмминга,
верхняя граница Варшамова-Гильберта,
Теорема об обнаруживающем коде.
Теорема об исправляющем коде
Рассмотрим некоторые понятия связанные с
использованием избыточных кодов
Расстоянием (Хэмминга)
между (двоичными) словами длины n называется количество позиций, в которых эти
слова различаются.
Это одно из ключевых понятий теории кодирования.
Если обозначить двоичные слова как a = a1 . . . an и b = b1 . . . bn, то
расстояние между ними обозначается d(a, b).
d(10101000, 10000001)=3
D(98712365,98652365)=2
D(mama,papa)=2
В более общем случае расстояние Хэмминга применяется
для строк одинаковой длины любых q-ичных алфавитов и
служит метрикой различия (функцией, определяющей расстояние
в метрическом пространстве) объектов одинаковой размерности.
Первоначально метрика была сформулирована Ричардом
Хэммингом во время его работы в Bell Labs для определения меры различия между кодовыми
комбинациями (двоичными векторами) в векторном пространстве кодовых
последовательностей:
в этом случае расстоянием Хэмминга d(x,y) между двумя
двоичными последовательностями (векторами) x и y длины n называется число
позиций, в которых они различны.
В такой формулировке расстояние Хэмминга вошло в
словарь алгоритмов и структур данных национального института стандартов и
технологий США (англ. NIST Dictionary of Algorithms and
Data Structures).
Расстояние Хэмминга является частным случаем метрики Минковского
Два слова, расстояние Хэмминга между которыми равно
1,
называют
соседними.
3-битовый двоичный куб; все вершины,
соединённые ребром
имеют расстояние 1

В некоторых системах счисления, например, в коде
Грея,
целые кодированные числа, различающиеся на 1, имеют расстояние Хэмминга равное
1. Говорят, что такие числа являются «соседними».
Особое место среди позиционных двоичных кодов занимает
циклический код Грея. Характерной особенностью этого кода является
изменение только одной позиции при переходе от одного кодовой комбинации к
другой. Это свойство кода Грея широко используют как для построения некоторых
типов АЦП, так и для повышения надежности преобразователей с помощью
резервирования и самоконтроля. Используется в технике аналогово-цифровых
преобразователях, где он позволяет свести к «1» младшего разряда погрешность
неоднозначности при считывании.
Рассмотрим алгоритм построения кода Грея.
Код Грея можно построить на основе натурального двоичного кода числа.
Для перехода от натурального двоичного кода к коду Грея существуют правила:
• если в предыдущем разряде двоичного кода стоит 0, то в данном разряде цифра
сохраняется;
• если в предыдущем разряде двоичного кода стоит 1, то в данном разряде цифра
меняется на противоположную (цифра 0 изменится на 1 и
наоборот).
Рассмотрим пример.
Возьмем целые десятичные числа от 0 до 15. Запишем их двоичное представление,
выделив для хранения каждого числа полбайта:
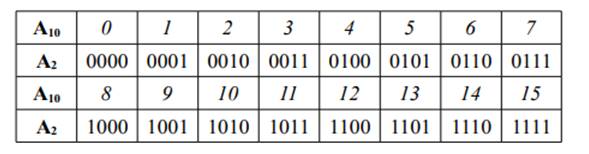
Перейдем к построению кода Грея.
Натуральный двоичный код числа 0 (0000) не содержит ни одной единицы.
Следовательно, согласно правилу построения ни одна его цифра в коде Грея не
изменится. Код числа 1 (0001) содержит одну единицу только в самом последнем
справа разряде. Разряда для которого она являлась бы
предыдущей нет. Значит натуральный двоичный код числа
1 совпадает с кодом Грея числа 1.
А вот двоичный код числа 2 (0010) содержит единицу во третьем слева разряде. Согласно правилу построения кода
Грея, следующий за ней разряд должен изменить свою цифру на
противоположную. Значит код Грея для числа 2 будет
0011. Аналогичным образом можно получить код Грея для оставшихся чисел.
Результат такого преобразования представлен в
таблице.
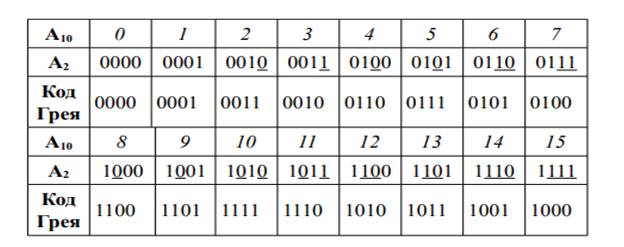
Для перехода от кода Грея к натуральному
двоичному коду используют следующее правило: если слева от данной цифры
находится четное число единиц, то цифра сохраняется, в противном случае цифра
меняется.
Например
имеет код Грея некоторого числа:
1010.
Необходимо получить само число. Рассмотрим разряды кода слева направо.
Обозначим их q1, q2, q3, q4.
Левее q1 других цифр нет, значит она не меняется.
Второй разряд q2=0, слева от него находиться единственная единица, значит
значение этого разряда меняется на на
1.
Следующий разряд q3 =1, в коде Грея ему также предшествует одна единица в
разряде q1.
Следовательно цифра разряда q3 поменяется на
противоположную (q3 = 0).
А вот четвертому разряду кода Грея предшествуют уже две единицы в разрядах q1 и
q3, соответственно, значение этого разряда должно измениться. Окончательно
имеем следующий двоичный код: 1100. Это двоичное представление числа 12.
Свойства Расстояния Хэмминга

Весом двоичного слова
a = a1 . . . an называется количество единиц в нем.
Обозначение w(a). Можно сказать, что w(a) = ∑ai
.
a=1010
w(a)=2
d=0001 w(d)=1
b=1111 w(b)=4
Пусть операция + при применении к двоичным словам
будет означать поразрядное сложение без переноса, т. е. сложение по модулю 2
или “исключающее ИЛИ” (XOR).
Исключа́ющее
«или» (сложе́ние
по мо́дулю 2, XOR, строгая
дизъюнкция, поразрядное дополнение, инвертирование по
маске, жегалкинское сложение, логическое
вычитание, логи́ческая неравнозна́чность) — булева
функция, а также логическая и битовая
операция, в случае двух переменных результат выполнения
операции истинен тогда и только тогда, когда один из аргументов истинен, а
другой — ложен. Для функции трёх (тернарное сложение по модулю 2) и более
переменных — результат выполнения операции будет истинным только тогда, когда
количество аргументов, равных 1, составляющих текущий набор, — нечётное.
Расстояние между двоичными словами a и b равно весу их поразрядной суммы, т.е.
d(a, b) = w(a + b).
a = 1010
b
= 1100
a+b = 0110
w(a+b)=2
d(a,b)=2
Если два слова различаются в каком-либо разряде, то
это добавит единицу к весу их поразрядной суммы.
a = 1000
b = 1100
a+b = 0100
w(a+b)=1
d(a,b)=1
Следовательно,
если a и b — слова длины n, то вероятность того, что слово a будет принято как
b, равна
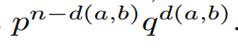
Например, вероятность того, что слово 1011 будет принято
как 0011, равна
![]()
Для возможности обнаружения ошибки в
одной позиции минимальное расстояние между словами кода должно быть большим 1.
Иначе ошибка в одной позиции сможет превратить одно кодовое слово в другое, что
не даст ее обнаружить.
Для того, чтобы код давал возможность
обнаруживать все ошибки кратности, не большей k, необходимо и достаточно, чтобы
наименьшее расстояние между его словами было k + 1.
(Теорема об обнаруживающем коде)
Для такого кода вероятность того, что ошибки в
сообщении останутся необнаруженными, равна
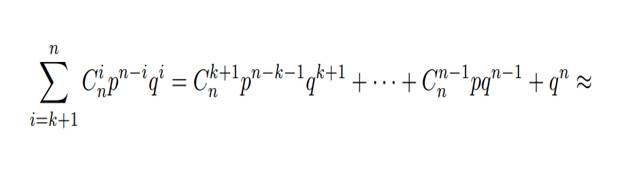
≈ [при малых q и не слишком маленьких k]
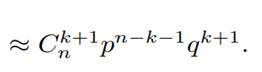
Для того, чтобы
код давал возможность исправлять все ошибки кратности, не большей k, необходимо
и достаточно, чтобы наименьшее расстояние между его словами было 2k + 1.
(Теорема об исправляющем коде)
Пример.
Рассмотрим (1, 3)-код, состоящий из
E, задающей отображение 0 → 000 и 1 → 111,
и D, задающей отображение 000 → 0,
001 → 0, 010 → 0, 011 → 1, 100 → 0, 101 → 1, 110
→ 1, 111 → 1.
Этот код (с тройным повторением) исправляет ошибки в одной позиции, т.к.
минимальное расстояние между словами кода равно 3.
Если код исправляет все ошибки кратности k и
меньшей, то вероятность ошибочного приема слова длины n очевидно не превосходит
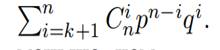
Вероятность правильного приема в этом случае не меньше,
чем
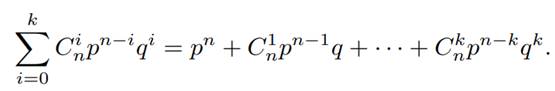
Передачу данных часто удобно рассматривать следующим
образом.
Исходное сообщение a = a1 . . . am кодируется
функцией E в кодовое слово b = b1 . . . bn.
Канал связи при передаче добавляет к нему функцией T строку ошибок e = e1 . . .
en так, что приемник получает сообщение r = r1 . . . rn, где ri = bi
+ ei (1 <= i <= n).
Система, исправляющая ошибки, переводит r в некоторое (обычно ближайшее)
кодовое слово.
Система, только обнаруживающая ошибки, лишь проверяет, является ли
принятое слово кодовым, и сигнализирует о наличии ошибки, если это не так.
Пример.
Рассмотрим (2, 3)-код с проверкой четности. Множество кодовых слов — {000, 011,
101, 110}. Ни одна из строк ошибок 001, 010, 100, 111 не переводит одно кодовое
слово в другое. Поэтому однократная и тройная ошибки могут быть обнаружены.
Пример.
Следующий (2, 5)-код обнаруживает две ошибки:
a1 = 00 → 00000 = b1, a2 = 01 → 01011 = b2,
a3 = 10 → 10101 = b3, a4 = 11 → 11110 = b4.
Этот же код способен исправлять однократную ошибку, потому что любые два
кодовых слова отличаются по меньшей мере в трех
позициях. Из того, что d(bi , bj ) >= 3 при i ≠ j, следует, что однократная ошибка
приведет к приему слова, которое находится на расстоянии 1 от кодового слова,
которое было передано. Поэтому схема декодирования, состоящая в том, что
принятое слово переводится в ближайшее
к нему кодовое, будет исправлять однократную ошибку. В двоичном симметричном
канале вероятность правильной передачи одного блока будет не меньше чем
![]()
Установлено, что в (n − r, n)-коде,
минимальное расстояние между кодовыми словами которого
2k + 1, числа n, r (число дополнительных разрядов в кодовых словах) и k должны
соответствовать неравенству
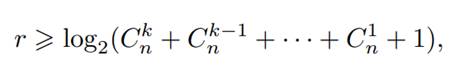
называемому
неравенством или нижней границей Хэмминга
Если числа n, r и k соответствуют неравенству
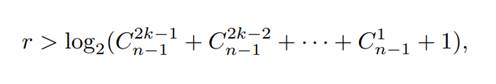
называемому
неравенством или верхней границей Варшамова-Гильберта,
то существует (n − r, n)-код, исправляющий все ошибки веса k и менее.
Нижняя граница задает
необходимое условие для помехозащитного кода с заданными характеристиками, т.е.
любой такой код должен ему соответствовать, но не всегда можно построить код по
подобранным, удовлетворяющим условию характеристикам.
Верхняя граница задает достаточное условие для существования
помехозащитного кода с заданными характеристиками, т. е. по любым подобранным,
удовлетворяющим условию характеристикам можно построить им соответствующий код.