Лекция11. Совершенные
и квазисовершенные коды. Свойства совершенного кода. Код
Хэмминга
Групповой (m,n)-код, исправляющий все ошибки
веса, не большего k, и никаких других, называется совершенным.
Свойства совершенного кода:
1. Для
совершенного (m,n)-кода, исправляющего все ошибки
веса, не большего k
, выполняется соотношение ![]() Верно и обратное утверждение;
Верно и обратное утверждение;
2. Совершенный
код, исправляющий все ошибки веса, не большего
k,
в столбцах таблицы декодирования содержит все слова, отстоящие от кодовых на
расстоянии, не большем k
. Верно и обратное утверждение;
3. Таблица
декодирования совершенного кода, исправляющего все ошибки в не более чем k
позициях, имеет в качестве лидеров все строки, содержащие не более k
единиц. Верно и обратное утверждение.
Совершенный код (m,n)- это лучший код, обеспечивающий
максимум минимального расстояния между кодовыми словами при минимуме длины
кодовых слов. Совершенный код легко декодировать: каждому полученному слову
однозначно ставится в соответствие ближайшее кодовое. Чисел m ,
n
и k
![]() , удовлетворяющих условию совершенности кода
очень мало. Но и при подобранных m, n
и k совершенный код можно построить
только в исключительных случаях.
, удовлетворяющих условию совершенности кода
очень мало. Но и при подобранных m, n
и k совершенный код можно построить
только в исключительных случаях.
Если m
,n и k не удовлетворяют условию совершенности, то
лучший групповой код, который им соответствует называется квазисовершенным, если
он исправляет все ошибки кратности, не большей
k,
и некоторые ошибки кратности k+1. Квазисовершенных кодов также
очень мало.
Двоичный блочный
(m,n)
-код называется оптимальным,
если он минимизирует вероятность ошибочного декодирования. Совершенный или
квазисовершенный код - оптимален. Общий способ построения оптимальных кодов
пока неизвестен.
Для любого целого положительного числа r
существует совершенный (n,m)-код, исправляющий одну ошибку,
называемый кодом Хэмминга (Hamming), в котором
![]() и
и ![]() .
.
Действительно,
![]() .
.
Порядок построения кода Хэмминга следующий:
1. Выбираем
целое положительное число r.
Сообщения
будут словами длины ![]()
, а кодовые слова - длины ![]()
2. В
каждом кодовом слове ![]()
бит с
индексами-степенями двойки ![]()
- являются контрольными, остальные - в естественном
порядке - битами сообщения. Например, если r=4 , то биты
![]() -
контрольные, а
-
контрольные, а
![]() -
из исходного сообщения;
-
из исходного сообщения;
Порядок построения кода Хэмминга следующий:
Строится матрица
M
из ![]() строк и
r
столбцов. В i-ой строке стоят цифры двоичного
представления числа i
. Матрицы для r=2, 3 и 4 таковы:
строк и
r
столбцов. В i-ой строке стоят цифры двоичного
представления числа i
. Матрицы для r=2, 3 и 4 таковы:
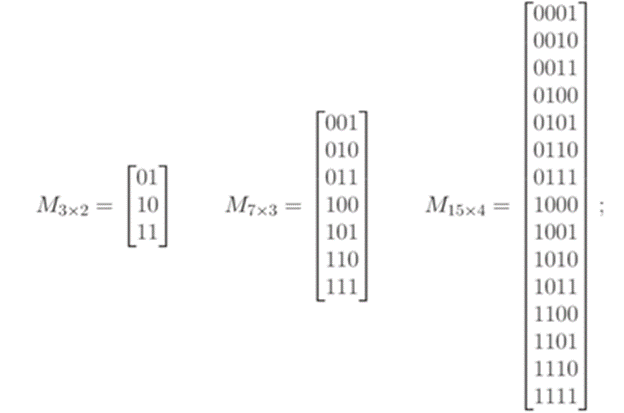
Записывается система уравнений bM=0
, где M - матрица из предыдущего пункта.
Система состоит из r уравнений.
Например, для
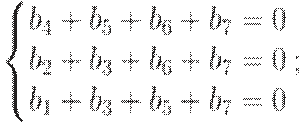
Чтобы закодировать сообщение a,
берутся в качестве bj
, j
не равно степени двойки, соответствующие биты сообщения и отыскиваются,
используя полученную систему уравнений, те bj , для которых j
- степень двойки. В каждое уравнение входит только одно bj, j=2^i. В выписанной системе b4
входит в 1-е уравнение, b2 - во второе и b1-
в третье. В рассмотренном примере сообщение
a=0111
будет закодировано кодовым словом b=0001111
Декодирование кода Хэмминга проходит по следующей
схеме. Пусть принято, слово b+e
где b- переданное кодовое слово, а e
- строка ошибок. Так как bM=0
, то (b+e)M=bM+eM=eM . Если результат нулевой, как
происходит при правильной передаче, считается, что ошибок не было. Если строка
ошибок имеет единицу в i -й позиции, то результатом
произведения eM будет i-я
строка матрицы M или двоичное представление числа i.
В этом случае следует изменить символ в
i-й
позиции слова b+e , считая позиции слева, с единицы.
(4,7)-код Хэмминга имеет в качестве одного из
кодовых слов b=0001111. Матрица M(7,3)
приведена на шаге 3 хода построения кода Хэмминга. Ясно, что bM=0 . Добавим к b
строку ошибок e=0010000. Тогда b+e=00111111 и (b+e)M=011=3 , т.е. ошибка находится в
третьей позиции. Если e=
0000001, то b+e=0001110 и позиция ошибки – (b+e)M=111=7 и т.п. Если ошибка допущена в более чем в
одной позиции, то декодирование даст неверный результат.
Код Хэмминга - это групповой код.
Это следует из того, что (m,n)
-код Хэмминга можно получить матричным кодированием, при помощи m x n -матрицы, в которой столбцы с
номерами не степенями 2 образуют единичную подматрицу. Остальные столбцы
соответствуют уравнениям шага 4 построения кода Хэмминга, т.е. 1-му столбцу
соответствует уравнение для вычисления 1-го контрольного разряда, 2-му - для
2-го, 4-му - для 4-го и т.д. Такая матрица будет при кодировании копировать
биты сообщения в позиции не степени 2 кода и заполнять другие позиции кода
согласно схеме кодирования Хэмминга.
Кодирующая матрица для (4,7) -кода Хэмминга
Ее столбцы с номерами 3, 5, 6 и 7 образуют единичную
подматрицу. Столбцы с номерами 1, 2 и 4 соответствуют уравнениям для вычисления
контрольных бит, например, уравнению b1=b3+b5+b7
соответствует столбец 1101, т.е. для вычисления первого контрольного
разряда берутся 1, 2 и 4 биты исходного сообщения или биты 3, 5 и 7 кода.
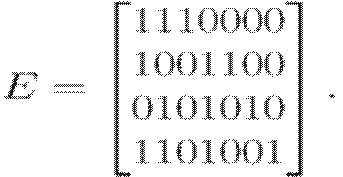
К (m,n)
-коду Хэмминга можно добавить проверку четности. Получится (m,n+1) -код с наименьшим весом
ненулевого кодового слова 4, способный исправлять одну и обнаруживать две
ошибки.
Коды Хэмминга накладывают ограничения на длину слов
сообщения: эта длина может быть только числами вида ![]() : 1, 4, 11, 26, 57, Но в реальных системах информация передается
байтам или машинными словами, т.е. порциями по 8, 16, 32 или 64 бита, что
делает использование совершенных кодов не всегда подходящим. Поэтому в таких
случаях часто используются квазисовершенные коды.
: 1, 4, 11, 26, 57, Но в реальных системах информация передается
байтам или машинными словами, т.е. порциями по 8, 16, 32 или 64 бита, что
делает использование совершенных кодов не всегда подходящим. Поэтому в таких
случаях часто используются квазисовершенные коды.
Квазисовершенные
коды
Квазисовершенные
(m,n) -коды, исправляющие одну ошибку,
строятся следующим образом. Выбирается минимальное n
так, чтобы
Каждое кодовое слово такого кода будет
содержать k=m-n контрольных разрядов. Из
предыдущих соотношений следует, что
![]()
Каждому из n разрядов присваивается
слева-направо номер от 1 до n
. Для заданного слова сообщения составляются k
контрольных сумм S1, S2, …,Sk. по модулю 2 значений специально
выбранных разрядов кодового слова, которые помещаются в позиции-степени 2 в
нем:
для Si (1≤ I ≤ k)
выбираются разряды, содержащие биты исходного сообщения, двоичные
числа-номера которых имеют в i-м разряде единицу. Для суммы S1
это будут, например, разряды 3, 5, 7 и т.д., для суммы S2
- 3, 6, 7 и т.д. Таким образом, для слова сообщения a=a1a2a3…am будет
построено кодовое слово b=S1S2a1S3a2a3a4S4a5…am.
Обозначим ![]()
сумму по модулю 2 разрядов получено слова,
соответствующих
контрольной сумме ![]() и самой этой контрольной суммы. Если
и самой этой контрольной суммы. Если
![]() …
…![]() =0,
то считается, что передача прошла без ошибок. В случае одинарной ошибки
=0,
то считается, что передача прошла без ошибок. В случае одинарной ошибки ![]() …
…![]() будет равно двоичному числу-номеру сбойного
бита. В случае ошибки, кратности большей 1, когда
будет равно двоичному числу-номеру сбойного
бита. В случае ошибки, кратности большей 1, когда ![]() …
…![]() >n,
ее можно обнаружить. Подобная схема декодирования не позволяет исправлять
некоторые двойные ошибки, чего можно было бы достичь, используя схему
декодирования с лидерами, но последняя значительно сложнее в реализации и дает
незначительное улучшение качества кода.
>n,
ее можно обнаружить. Подобная схема декодирования не позволяет исправлять
некоторые двойные ошибки, чего можно было бы достичь, используя схему
декодирования с лидерами, но последняя значительно сложнее в реализации и дает
незначительное улучшение качества кода.
Пример построения кодового слова
квазисовершенного (9,n)-кода, исправляющего все
однократные ошибки, для сообщения 100011010.
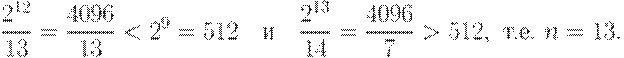
Искомое кодовое слово имеет вид 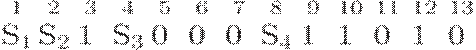
. Далее нужно
вычислить контрольные суммы.
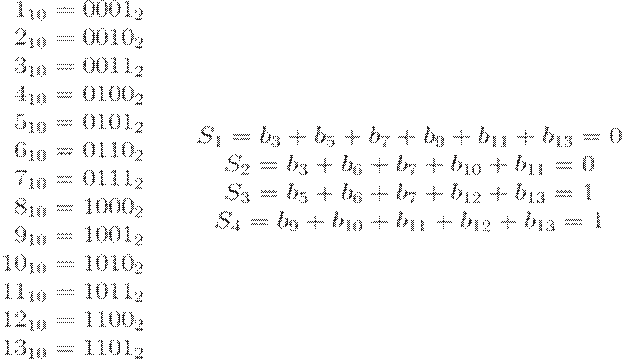
Таким образом, искомый код - 0011000111010.
Если в процессе передачи этого кода будет испорчен его пятый бит, то приемник
получит код 0011100111010. Для его декодирования опять вычисляются
контрольные суммы:
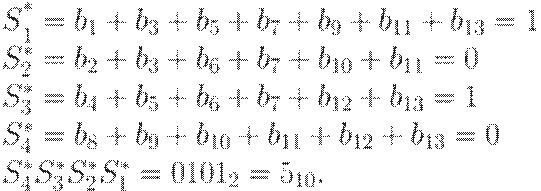
Приемник преобразует изменением пятого бита
полученное сообщение в отправленное передатчиком, из которого затем
отбрасыванием контрольных разрядов восстанавливает исходное сообщение
Совершенный код Хэмминга также можно строить по
рассмотренной схеме, т.к. для него
![]()
Для исправление одинарной ошибки к 8-разрядному коду
достаточно приписать 4 разряда
![]()
к 16-разрядному - 5, к 32-разрядному - 6, к
64-разрядному - 7.